KASE簡介 - Known-class Aware Self-ensemble for Open Set Domain Adaptation
Qing Lian, Wen Li, Lin Chen, Lixin Duan. Known-class Aware Self-ensemble for Open Set Domain Adaptation. In arXiv preprint.
尚未被 conference 接收,於 3 May 2019 提交至 arXiv.
Paper link : https://arxiv.org/abs/1905.01068
簡介
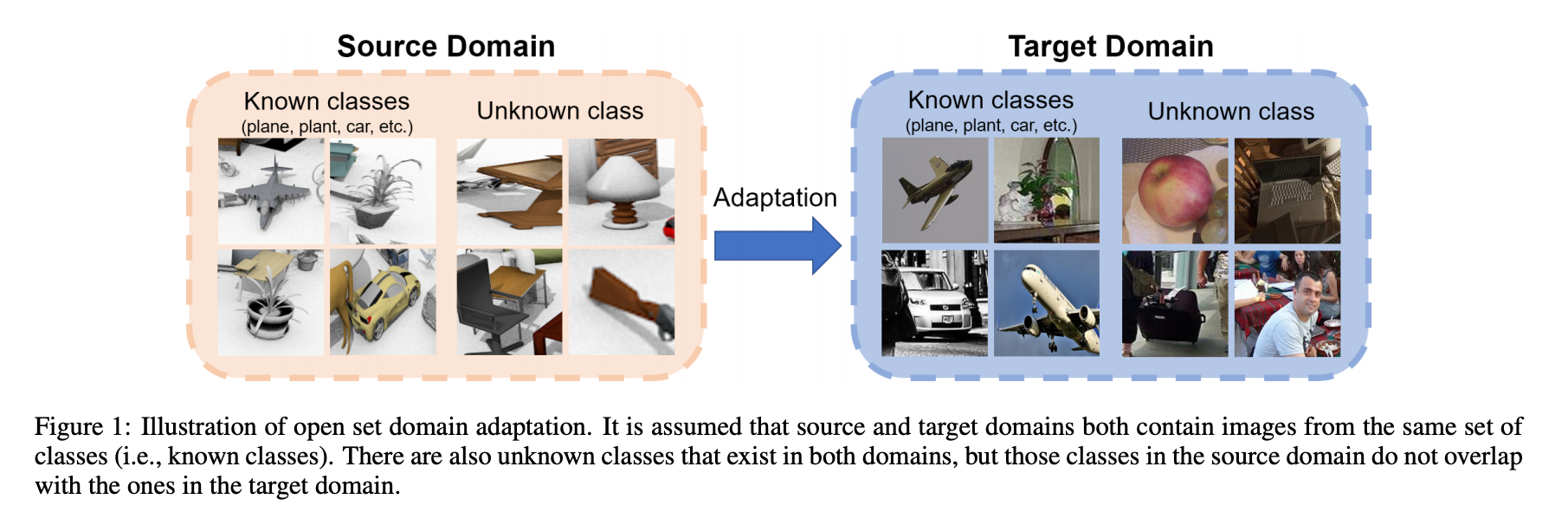
此文針對 Open Set Domain Adaptation 問題進行研究,
在 Domain Adaptation 的任務中會有兩個資料集 Source 及 Target Domain,
Source Domain 有圖片(Xs)以及標註(Ys - GT),
而 Target Domain 只有圖片(Xt)沒有標註。
而本文的任務為 Open Set ,
代表兩個資料集的類別只有部分重複,
Note: 以往 DA 的設定是針對兩個資料集中相同/共有的類別(Closed-set)去做適應。
因此我們會稱共有的類別為已知 - Known,
而不相同的類別為未知 - Unknown,
提出 Known-class Aware Self-Ensemble 稱作 KASE 的架構,
透過 Entropy 的概念將 Known 及 Unknown 的特徵分佈拉開,
藉此讓分類器可以對於 Known 的類別產生出較高的信心分數,
再將 Source Domain 所學會的知識適應至 Target Domain 的已知(Known)類別。
架構是基於 Self-Ensemble 的方法 - ICLR’18 Self-ensembling for visual domain adaptation
提出改良的 KASE 架構 - Known-class Aware Self-ensemble,
KASE 是將兩個新的模組加入 Self-Ensemble,
- Known-class Aware Recognition (KAR)
- Known-class Aware Adaptation (KAA)
KAR 當作已知類別的分類器,
使用 Cross-entropy 做訓練已知類別(Known),
目的是讓分類器能將已知類別(Known)輸出較高的機率,
並希望當未知類別(Unknown)的圖片輸入至分類器時,
所有預測出的已知類別(Known)信心分數都是低的。
KAA 是用來評估這圖片適不適合進行適應(Domain adaptation),
依據 KAR 所給出的信心分數,給出不同的權重進行適應。
架構
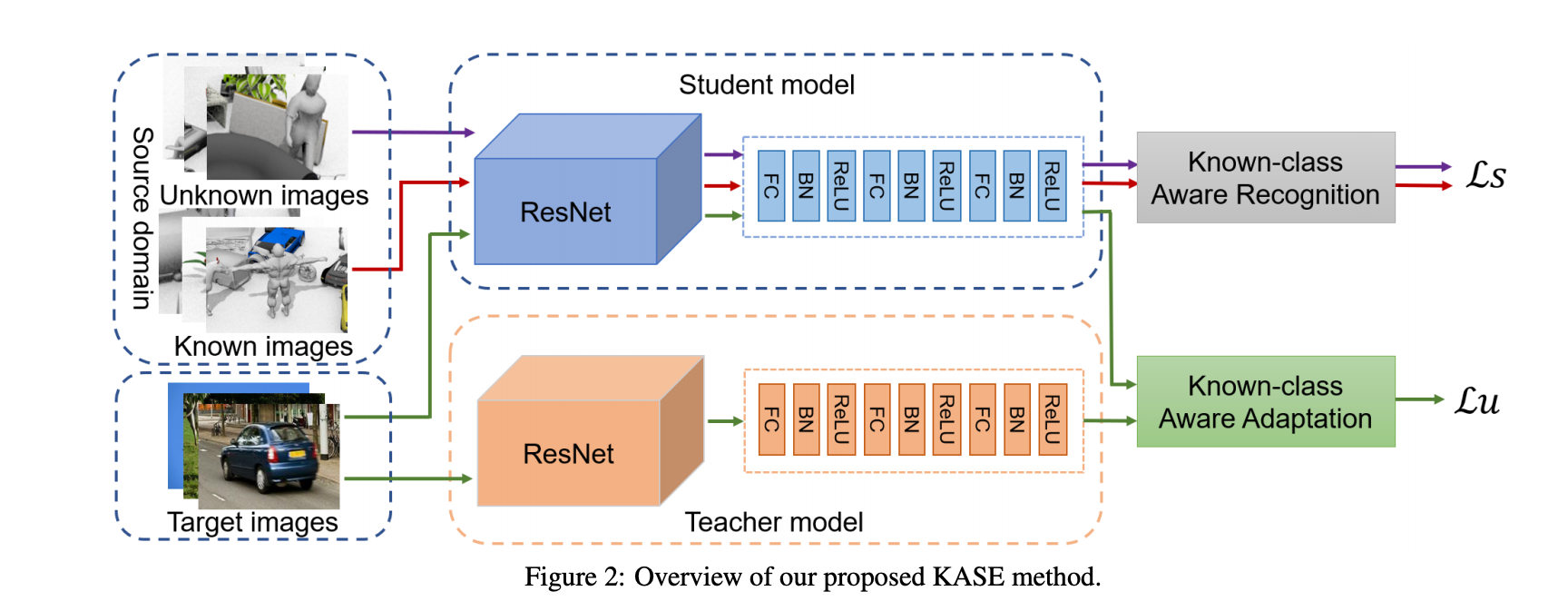
整體的訓練方法與 Self-ensembling for visual domain adaptation 這篇論文差不多,
Self-ensembling 主要是有兩個部分
- Student => 輸出稱作 z
- Teacher => 輸出稱作 z^
Note: Teacher 模型內的權重是基於 Student 網路的權重做 exponential moving average 調整,並不是用訓練的。
使用到了 Cross-entropy loss 以及 Self-ensembling loss,
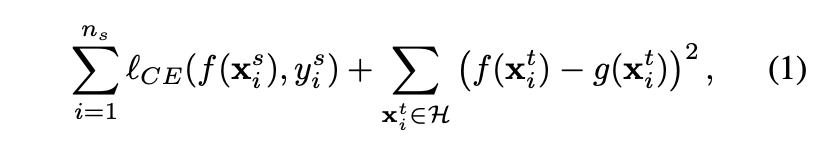
CE: Cross entropy。
H: 當分類器預測機率高於某個 threshold 時才會進行 Self-ensembling loss。
Cross-entropy loss 是使用 Source Domain Dataset 對 Student 的輸出(z)進行 Supervised 的訓練,
而 Self-ensembling loss(Unsupervised) - Mean square loss,
目的在於希望兩個模型能夠輸出一致的結果(z 及 z^),
概念是當 Teacher 模型能夠很肯定的說這張 Target Domain 的圖片是屬於哪個類別的話,
Teacher 就會透過 Self-ensembling loss 去訓練 Student,
讓 Student 慢慢適應至 Target Domain,
上面這樣的訓練方式是原先 Self-ensembling for visual domain adaptation 的設定,
當時的任務是 Closed-set Domain adaptation 為 Source 以及 Target Domain 的類別相同時,
但此論文不同之處是 Open-Set,
因此我們要先拉開 Known 以及 Unknown classes 之間的 Distribution,
讓分類器可以在預測 Known class 時信心分數是高的,
當分類器輸入 Unknown class 的圖片時,
分類器輸出所有的信心分數都要是低的,
為了上述的想法提出了 KAR Module (Known-class Aware Recognition),
只是在 Open-set 的設定,
對於 Target Domain 的 Unknown 類別,
我們要擔心 Teacher 是否能夠準確的辨認,
因為當 Teacher 辨認的好,
才能夠讓學生慢慢適應至 Target Domain,
但怎樣才算是辨認的好?
在這篇 Self-ensembling for visual domain adaptation 是使用一個定值當作 Threshold,
但問題是這個關鍵的值要怎麼定呢?
為了解決這個問題提出了 KAA Module(Known-class Aware Adaptation)
KAR - Known-class Aware Recognition
最簡單的想法是訓練分類器分出 Known 以及 Unknown,
但是以 DA 的任務來說,
我們只有 Source Domain 的 GT,
意味著我們只能看到 Source Domain 的 Known / Unknown 類別,
可是問題是,這樣的話當輸入 Target Domain 的 Unknown 類別時,
我們還能準確的分出這是 Unknown 嗎?
因為雖然都是 Unknown 類別,
但 Target Domain 的 Unknown 類別,
可能是 Source Domain 沒有的類別。
為了能夠應付這種狀況,提出使用 Entropy loss 進行訓練,
當是 Source Domain 的已知類別(Known)時 Entropy 要低 => Cross-entropy loss,
而 Source Domain 的 Unknown 類別 Entropy 就要高 => Entropy loss,
我們預期透過這種方式也可以處理好 Target Domain 的 Unknown 類別,
因為我們有使用 Cross-entropy loss 去訓練分類器,
而 Entropy loss 用意就是在分開 Known 以及 Unknown 的 Distribution。
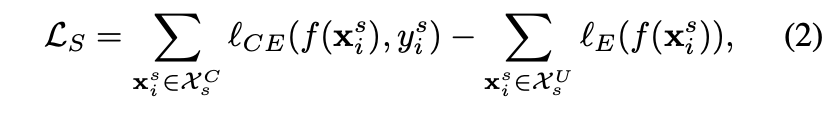
KAA - Known-class Aware Adaptation
為了要判斷 Teacher 的預測機率怎樣才是好,
需要一個準則,以往是給定一個定值,
只是說這個定值要怎麼給,會變成一個難題,
這邊提出使用 Entropy 的方式,
當 Entropy 小的時候,
代表著分類分得很好,
此時的 w 就會大,
透過這種方式可以避免掉去設定一個常數 - Threshold。
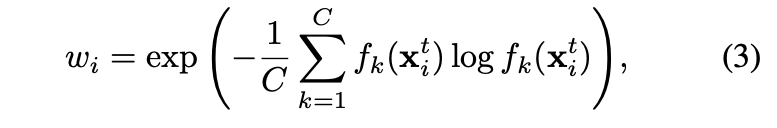
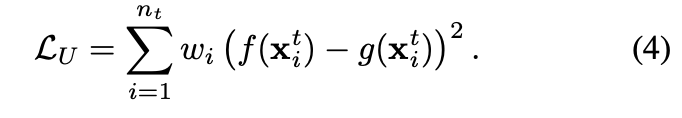
Loss Funtion
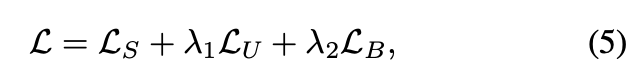
Note: L_B 是指 class balance loss,可看原本的論文 Self-ensembling for visual domain adaptation
成果
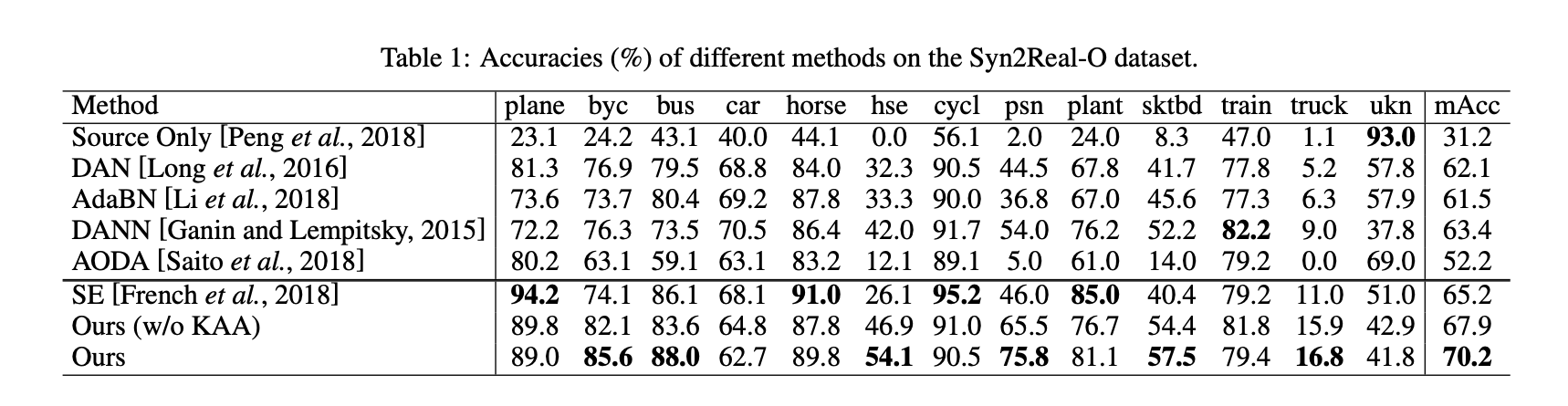
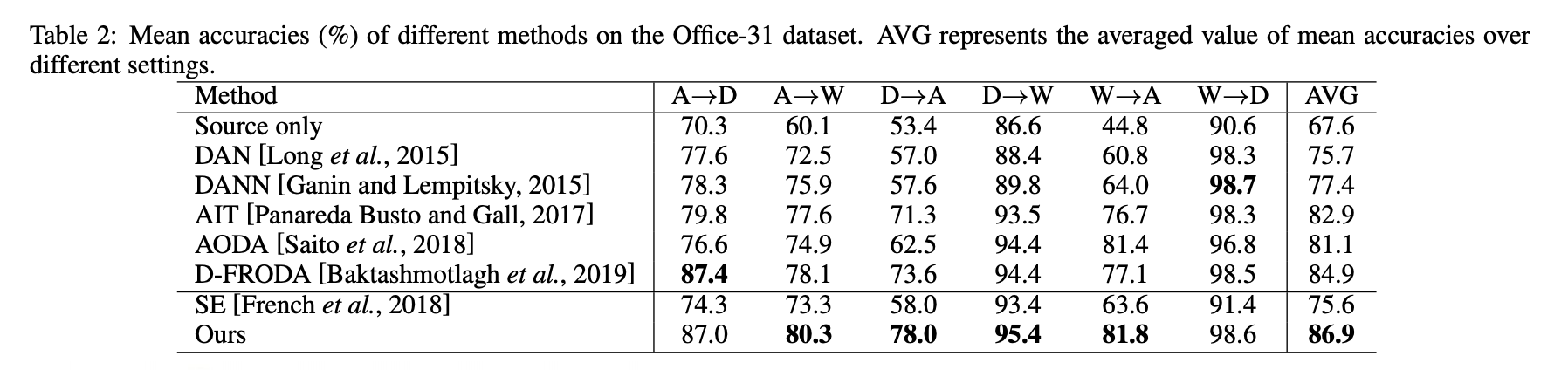
綠色代表 Unknown 類別
參考資料:
Known-class Aware Self-ensemble for Open Set Domain Adaptation