BTDA簡介 - Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks
Ziliang Chen, Jingyu Zhuang, Xiaodan Liang, Liang Lin. Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks. In CVPR’19.
CVPR 2019 paper
Paper link: https://arxiv.org/abs/1907.03389
Github(Pytorch): https://github.com/zjy526223908/BTDA
簡介
此文針對 Open Set Domain Adaptation 問題進行研究,
在 Domain Adaptation 的任務中會有兩個資料集 Source 及 Target Domain,
Source Domain 有圖片(Xs)以及標註(Ys - GT),
而 Target Domain 只有圖片(Xt)沒有標註,
其目標是希望讓模型在兩個 Domain 都能表現的不錯,
而要達到這件事,
模型就要學會能夠處理好兩個不同 Domain 的特徵(Domain-invariant features)。
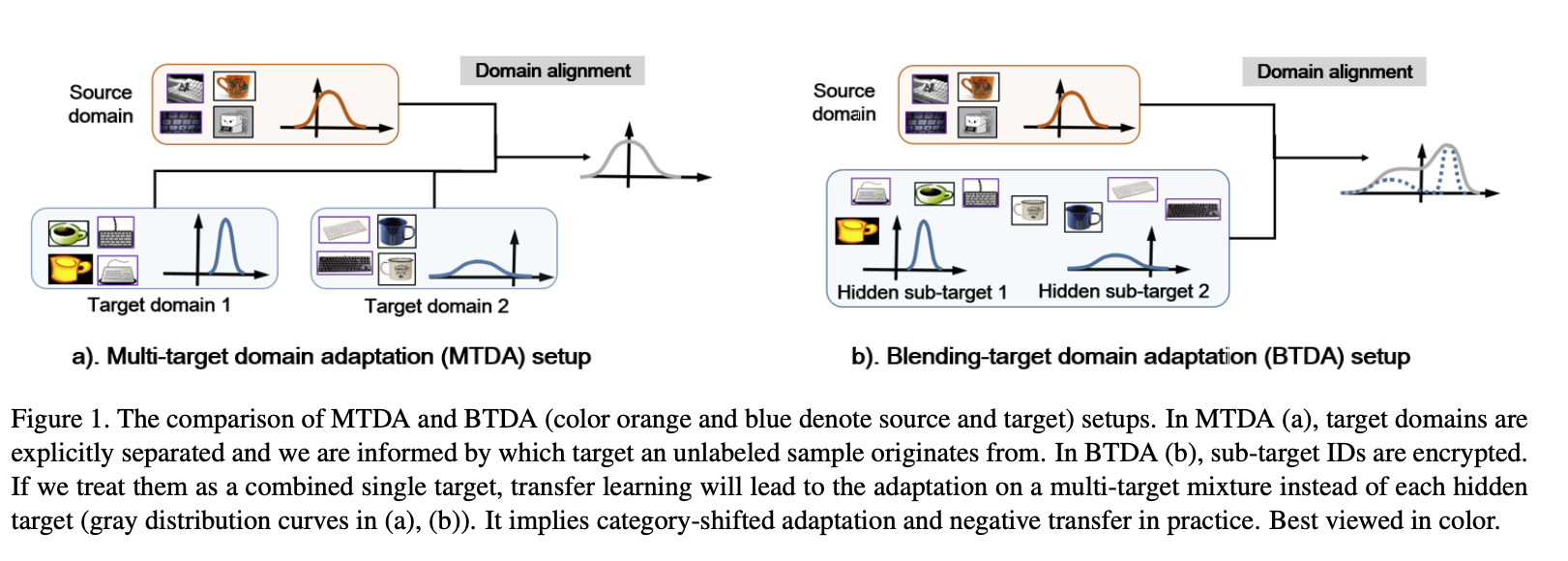
此論文要解決的問題相似於 Multi-target Domain,
都是考量到 Target Domain 可能混合著多的資料集,
但在 Multi-target Domain 的任務中我們可以知道目前這圖片是從哪個 Subset 來的,
但此論文認為這樣的設定還不夠貼近實務的狀況,
因此提出的設定為 Blending-target Domain,
它認為我們的 Target Domain 可能會包含 1 個以上的資料集混合在一起,
而我們也不知道資料集的每張圖片究竟是哪個 Domain 來的,
而這個設定難的地方在於每個資料集可能拍攝的背景、照相機的角度、圖片的亮暗都不一樣,
如果單純把混合的資料集用以往 Domain Adaptation 的訓練方法,
那訓練出來的結果會很糟,因為他沒有考量到每個資料集有不同的特性,
以及對於多個不同的 Subset 會有分類錯誤(category-misalignments)的問題。
所以整理一下目前的問題設定,
有 Source 及 Target Domain,
特別的地方是 Target Domain 內含不同種類的資料集(Subset),
但沒有特別去標注哪個圖片是屬於哪個 Subset,
大雜燴的概念,可以想像成爬蟲爬了一堆資料,但都沒整理過。。。
上述的問題設定為 Blending-target Domain Adaptation (BTDA)。
為了解決 BTDA 的任務,
此我們模型應該要能夠有效的解決這個問題,
提出 Adversarial Meta-Adaptation Network (AMEAN) 的學習框架,
一如既往地使用 GAN 的框架來學習 Domain-invariant features,
特別的地方是使用了 Meta-learning 的概念來學習目前這個 Feature 屬於哪個 Subset,
根據不同 Subset 調整學習的速率,
但我們的任務設定並不知道每張圖片屬於哪個 Subset,
因此我們模型需要自己評估目前這張圖片是屬於 Subset,
這邊可以想像成用 Cluster 分群的方式將圖片分類,
此處我們稱為 Meta-sub-target domains,
再透過不同的分群給予不同的權重進行訓練。
架構
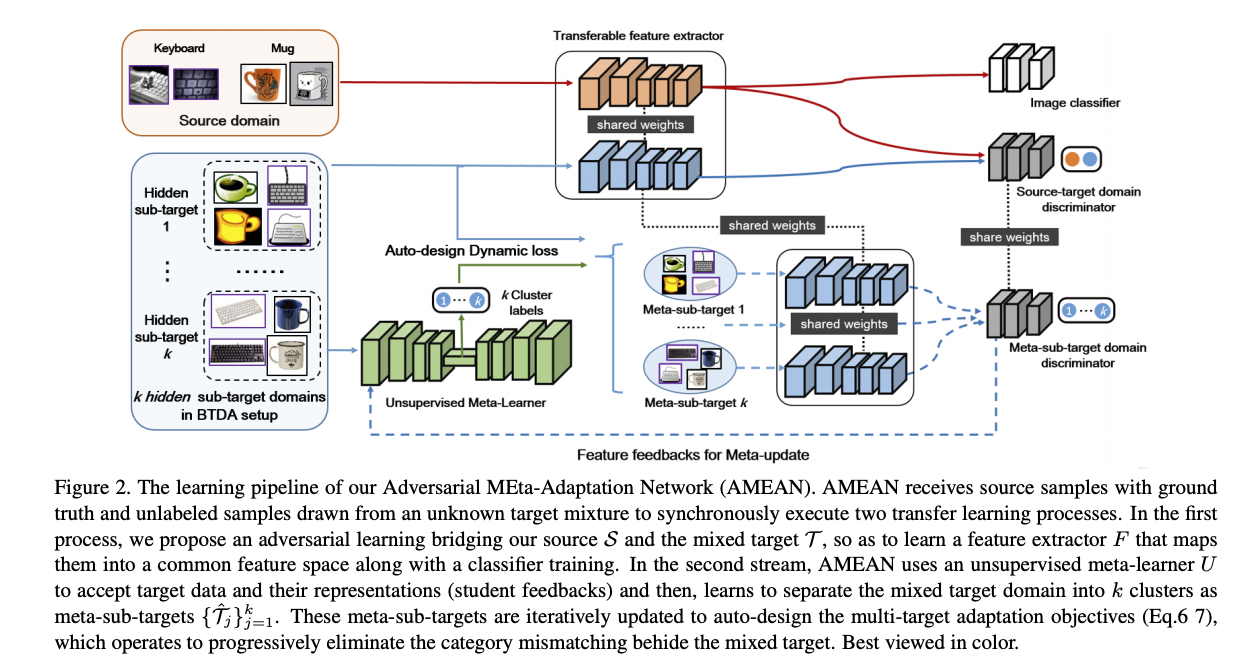
模型上半部的分支是 Domain Adaptation 常見的架構,
透過 GAN 的架構去讓模型學會 Domain-invariant features,
使用 Discriminator 學會分辨怎樣的 Features 是 Source / Target Domain,
再讓 Generator 去產生出 Domain-invariant features 去欺騙 Discriminator,
除此之外還會使用 Classification loss 來確保模型可以準確的預測出類別。
要注意的是此處是針對 Feature space - F 去做對抗式的學習。 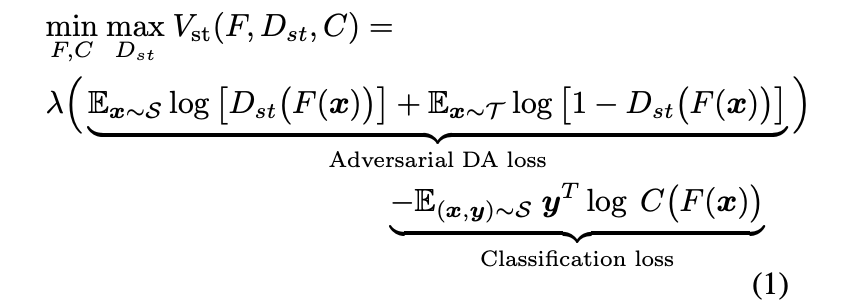
- F: Feature extractor
- C: Classification
- T: Target domain,此處的混合了 k 個 subset。
而我們的目標是希望我們的模型可以針對 k 個不同的 subset,
各自擬合他們的特徵分佈,
為了達到這件事提出了 Unsupervised meta-learner 用於將 Feature space / Embedding 去做分群,
將 Embedding 分為 k 類 => Meta-sub-targets,
希望我們分出的 k 類是代表著 k 個不同的 Subset。
有了預測出的 k 類,我們就能針對不同類別 / Subset 去做擬合。
雖然說是 Unsupervised meta-learner,
但本質上 Unsupervised Embedding for Clustering,
因為它方法是使用這篇的方法做分群 DEC - Unsupervised Deep Embedding for Clustering Analysis,
那為什麼叫做 Meta-learner 呢?
主要原因是因爲我們的混合資料集有 k 個 Subset,
如果我們的 Encoder-Decoder 可以學會 1 ~ k 個資料集的共通點,
並且可以將生成的 Embedding 都正確的還原的話,
就代表我們的 Meta-learner 是可以學會這 k 個資料集的共通特徵,
而 Meta-learning 的概念是看過不同的資料集/任務並且能適應好。
Meta-sub-targets - predict k-clustering
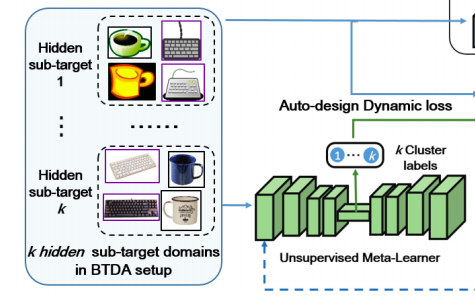
首先我們會把 Unsupervised-meta-learner 的 Encoder 所得到的特徵視為 Embedding,
再計算 Embedding 是屬於 k 類中的哪一類,
計算方式是看 Embedding 與 k 類的中心點 - u 的距離,
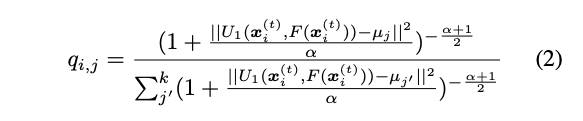
q 為屬於第 j 個群的機率。
Note: α 就只是看你要對這個式子多寬鬆,實驗設定為 1 就不多做探討。
只是說透過上面的式子,我們無法確保每個群的大小一樣,
因此提出作適當的 Normalize,
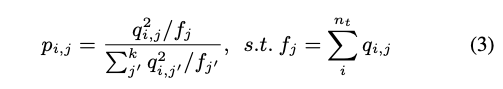
我們希望每群的數量大小差不多,
所以我們會加總每群的總數為 f,
p 當作是 Normalize 過後的值,
這部分可以看作求得每群的比例大小。
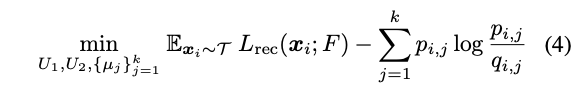
前方的 Lrec 是用於訓練 VAE,
後方為透過 KL-divergence 的方式,
讓 q 相似 p, 透過這種方式我們可以確保每群的大小是相近的。
下方公式為預測目前圖片是屬於哪個 Subset。
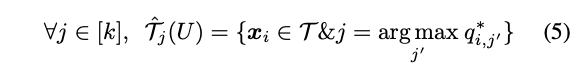
Meta-sub-targets adaptation
目的是希望 Discriminator 無法辨識目前的 Feature 是屬於第 1…k 個 Meta subset,
透過這種方式希望 Generator 能夠生成出 Domain-invariant features,
為了達到這目地,我們會希望 Discriminator 能夠準確的辨認出目前是屬於哪個 Subset,
也會希望我們的 Generator 能夠產生出讓 Discriminator 無法辨認的 Featrue,
藉此來對抗訓練。
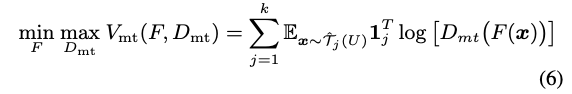
後半部的 1j => 目前是哪個類別,One hot encoding 的概念。
以前我們訓練分類器是採用 Cross-entropy 的方式訓練,
希望它輸出的機率可以和正確解答一樣 -> e.g. [0, 0, 1]。
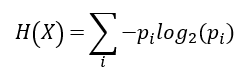
但是這邊我們是希望 Generator 能夠產生出讓 Discriminator 分辨不出來的模型,
所以我們要反向思考,把原本 cross entopy 的負號拿掉變成 Maximizing cross entropy。
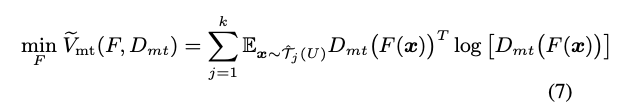
Collaborative Adaversarial Meta-Adaptation

整體的 Objcetive Function 會是下面這樣
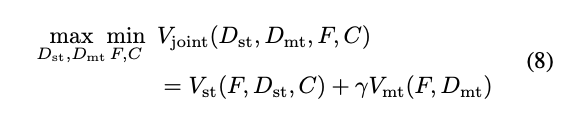
這篇其實寫了很多細節,有興趣的再自己去看論文!
成果
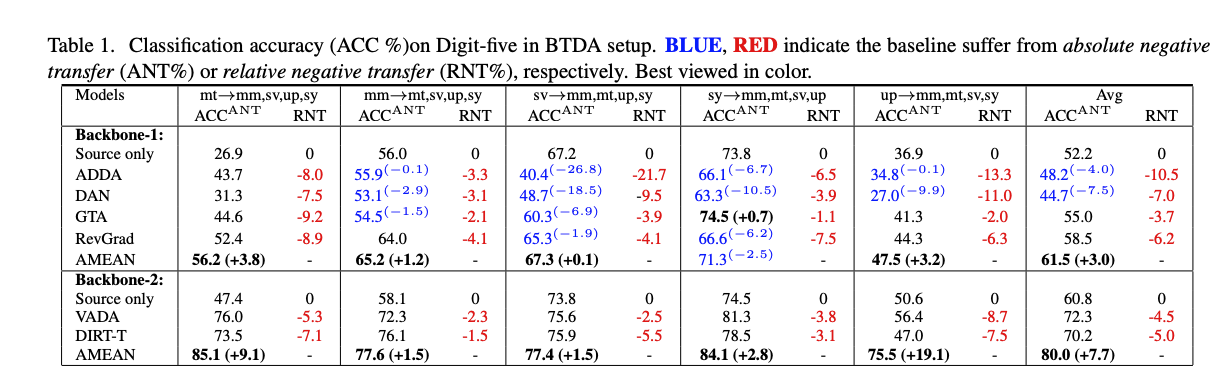
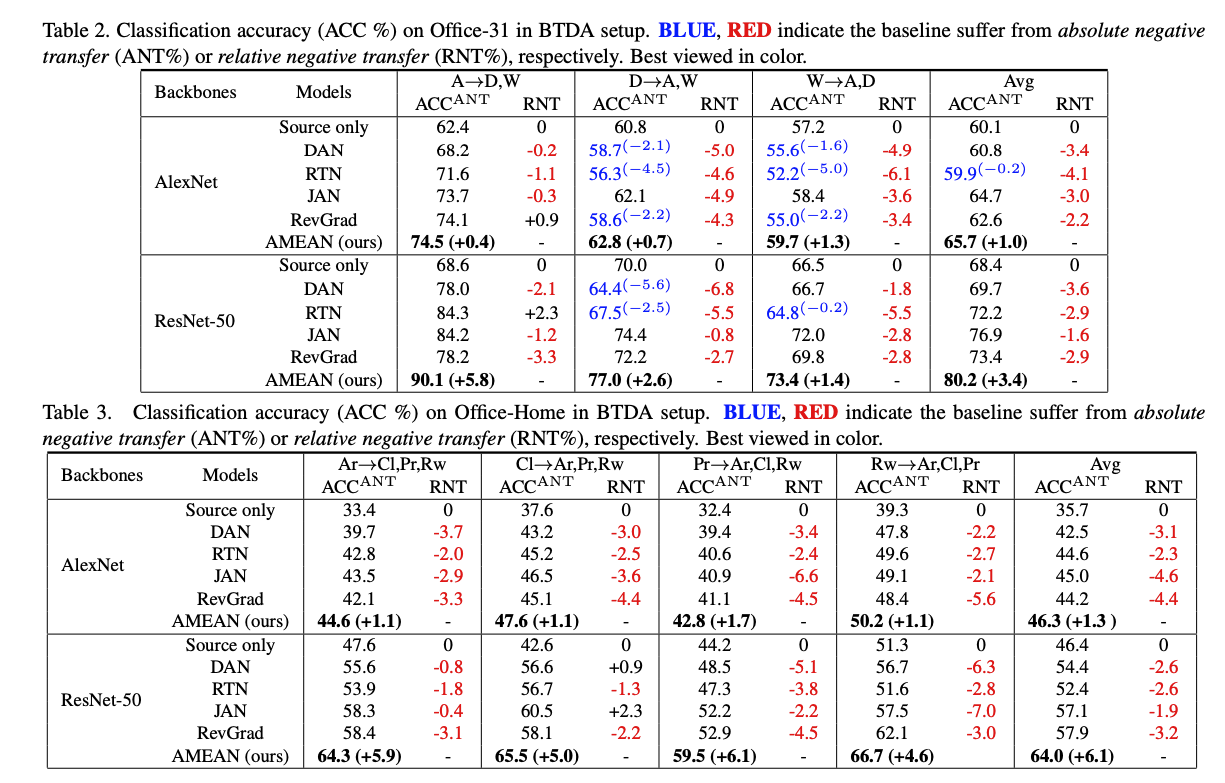

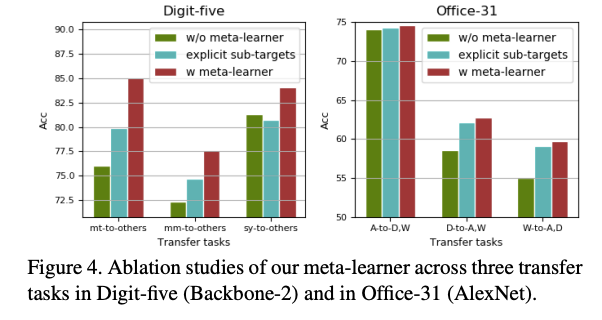
參考資料:
Blending-target Domain Adaptation by Adversarial Meta-Adaptation Networks