DEC簡介 - Unsupervised Deep Embedding for Clustering Analysis
Junyuan Xie, Ross Girshick, Ali Farhadi. Unsupervised Deep Embedding for Clustering Analysis. In ICML’16.
ICML 2016 paper
Paper link: https://arxiv.org/abs/1511.06335
Github(Caffe): https://github.com/piiswrong/dec
簡介
此文針對 Embedded clustering 的問題進行研究,
提出先使用 Encoder-Decoder 的架構,
獲得低維度的 latent vector / embedding 來進行分群,
整體概念跟 Center loss 的實作方式差不多,
會先創建出 K(群數) x d(latent vector 維度) 的參數當作中心點,
把他們當作中心點,
再使用 SGD 的方式來訓練整體網路以及調整中心點,
來達到分群的效果,
這問題難的地方是我們沒有 label 的資料,
只能仰賴 Unsupervised 的方式去做訓練。
方法
我們的圖片為 X,
我們希望將 X 分到 k 群,
但我們並不是希望直接針對圖片 X 去做分群,
我們會希望對 Latent space 做分群,
因為圖片像素之間的差異不見得代表他們相近,
將圖片的特徵 - Latent vector 抽取出來,
若兩個 Latent vector 相近就代表兩張圖片是相似的。
而 Latent vector - Z 的維度通常遠小於圖片大小。
我們能透過 Encoder-Decoder 的架構抽取出 Latent vector,
透過 Encoder-Decoder 的概念,
我們能透過 Encoder 去生成一個小維度的 Latent vector,
再將 Latent vector 丟入 Decoder 去還原出這張圖片。
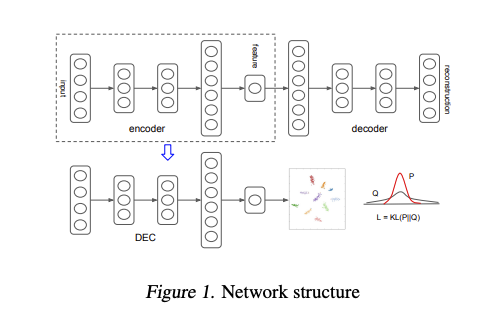
訓練方式其實很簡單,
做 MSE loss 確保輸入的圖片和還原的圖片長得一樣,
透過這種方式我們就能學會 Latent vector - 圖片特徵的概念。
而分群的時候通常會有群心 - u,
u 的維度為 k x Z 的維度。
如果 Latent vector 最靠近第 i 個群心的話,
我們就會說它是第 i 群。
訓練方式基於 Visualizing Data using t-SNE 去做改動的,
我們會透過下方的式子計算出第 i 張圖片的 Latent vector 是屬於第 j 個群的機率,
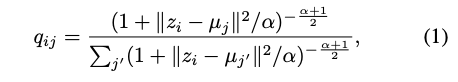
z - u 可以視作在 Latent space 間的距離,
如果越近就代表越有可能是屬於這個群集。
Note: α 就只是看你要對這個式子多寬鬆,實驗設定為 1 就不多做探討。
只是說透過上面的式子,我們無法確保每個群的大小一樣,
因此提出作適當的 Normalize,
我們希望每群的數量大小差不多,
所以我們會加總每群的總數為 f,
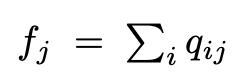
我們會求出 p 當作是 Normalize 過後的值,
這部分可以看作求得每群的比例大小。
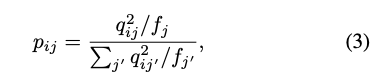
再透過 KL-divergence 的方式,
讓 q 相似 p, 透過這種方式我們可以確保每群的大小是相近的。
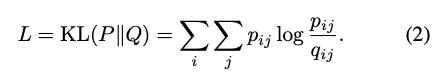
其他還有一些技巧,
像是一開始的 u 也不是隨機的,
是先透過得到所有 X 的 Latent vector 之後,
使用 K-means 的方式求得。
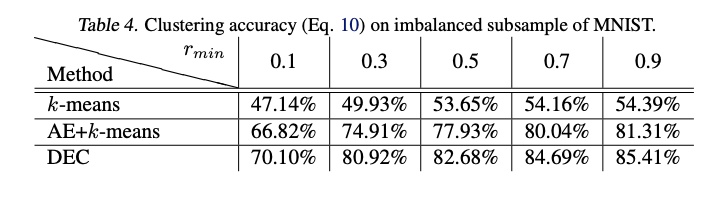
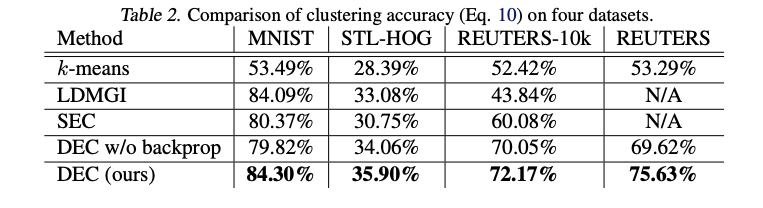
成果
在 4 個資料集上評估結果,


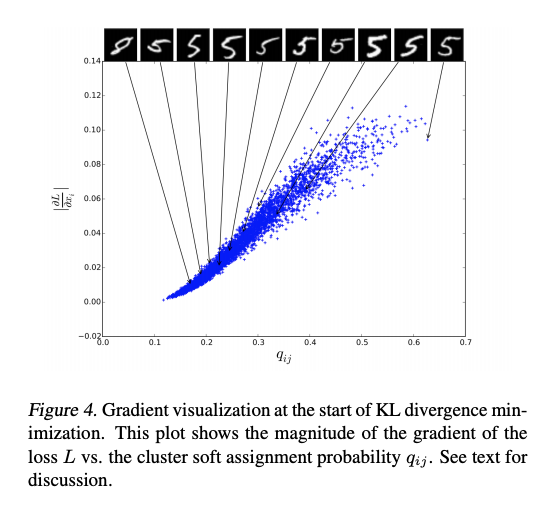
下圖為隨機抽取一群,我們可發現當 q 的信心分數越大時,
外觀越像 5,這意味著我們選取到的群心是 5,
也代表著我們的分群其實是有學到東西的。
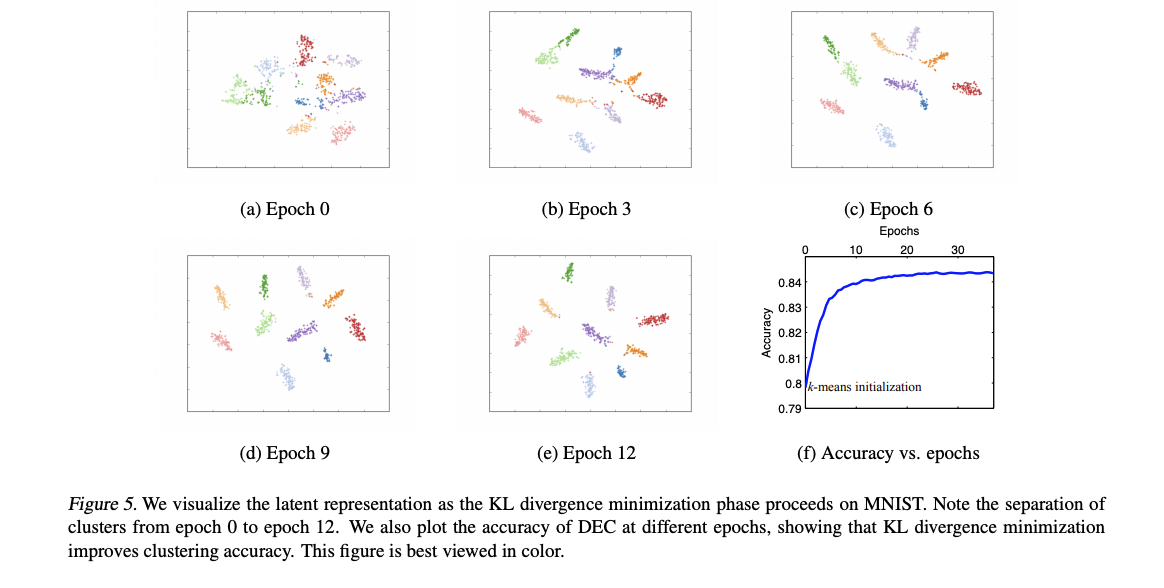
只是說這論文還有探討群的大小不一的問題,
我們可以知道 p 是希望每群的大小是一致的,
但在資料集中如果每個類別的大小不一致的話,
我們的 p 又希望每群的大小要相似,
這時候分類出來的結果就不會這麼好,
雖然相較以往的方法還是不錯拉,
Rmin 指的是將一個類別的資料集取一個比例 - subset 的概念。