OSNet簡介 - Omni-Scale Feature Learning for Person Re-Identification
Kaiyang Zhou, Yongxin Yang, Andrea Cavallaro, Tao Xiang. Omni-Scale Feature Learning for Person Re-Identification. In ICCV’19.
ICCV 2019 paper
Paper link: https://arxiv.org/abs/1905.00953
Github(Pytorch): https://github.com/KaiyangZhou/deep-person-reid
簡介
此文針對 Re-ID 的任務提出一個新的架構,
此架構的想法模型不僅是要學習不同尺度的特徵,
還要動態的辨別目前混合哪個尺度的特徵會是最有幫助的。

舉例來說當辨別一個人的時候,
可能我們會希望看一些細節的部分(鞋子, 眼鏡…
但我們也會想看到整體的樣子(身材。
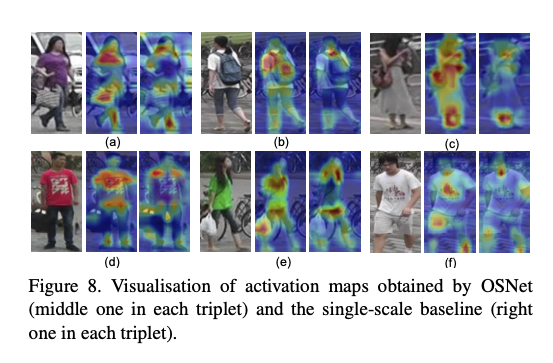
看一下上圖的右下角的最右邊那張圖,
我們人在看會覺得衣服上的 Logo 會是一個很重要的特徵,
但是模型看的話可能只會 Focus 在那個 Logo,
而忽略的 Logo 應該和白色 T-shirt 一起做識別,
就是這個想法帶出了希望可以透過融合不同尺度的特徵,
來豐富目前的特徵,
讓模型不只學會注重細節,
在需要的時候還能夠捕捉更大範圍的資訊,
用以輔助 Re-ID 的識別。
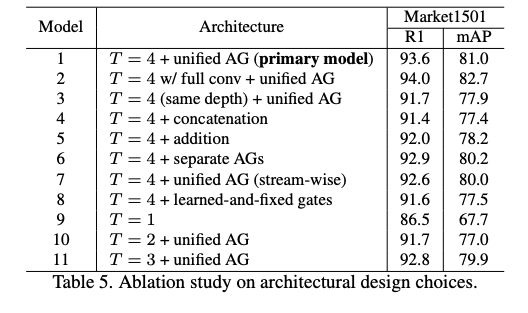
此論文有一些設計的核心想法:
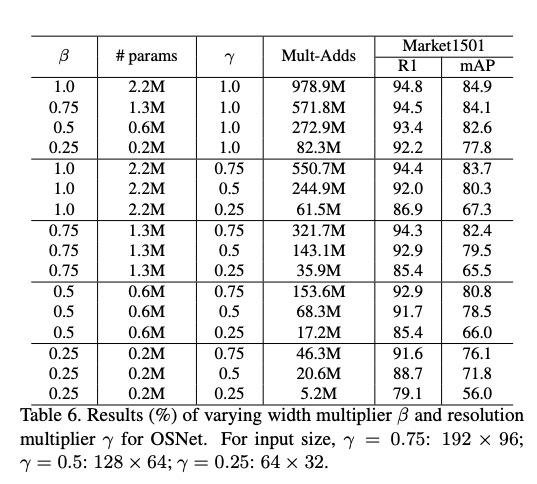
- 模型輕量化 (希望能在相機端直接執行
- 不同尺度間的特徵要互相搭配
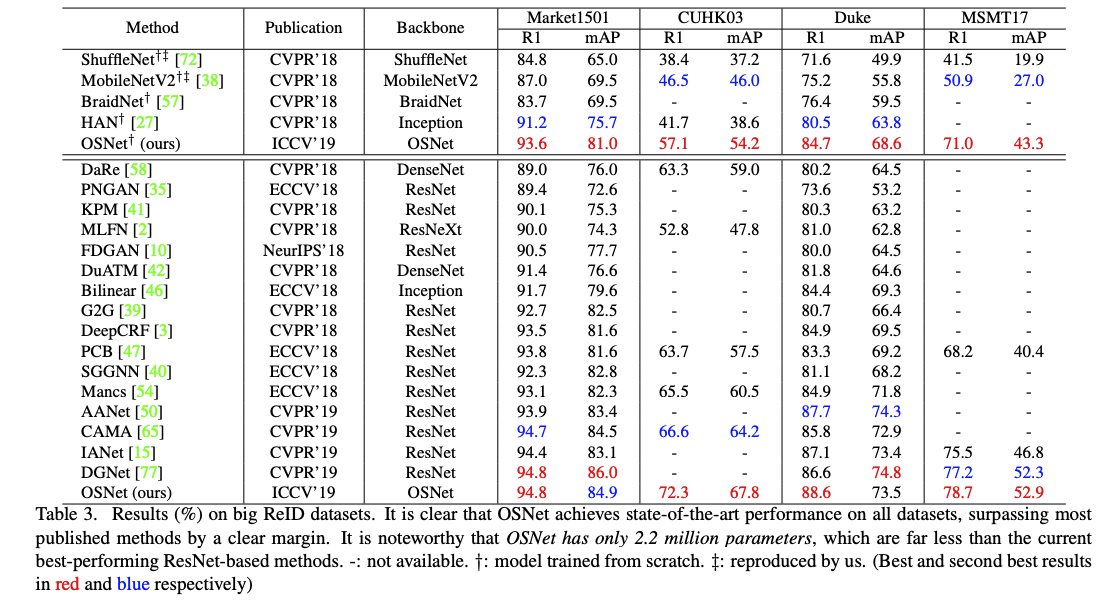
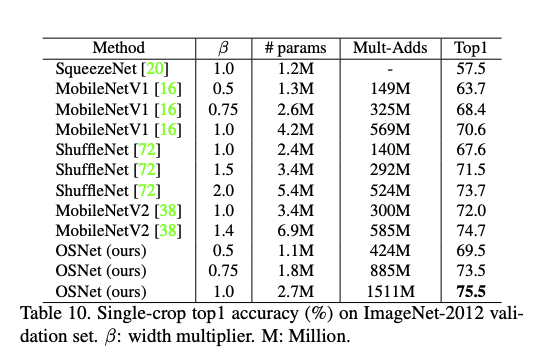
在現存的許多 Re-ID 的資料集都獲得很好的成績!
題外話:
我用此模型訓練的 Embedding 的時候,
如果不使用 Label smoothing 就會爆炸。。。
概念
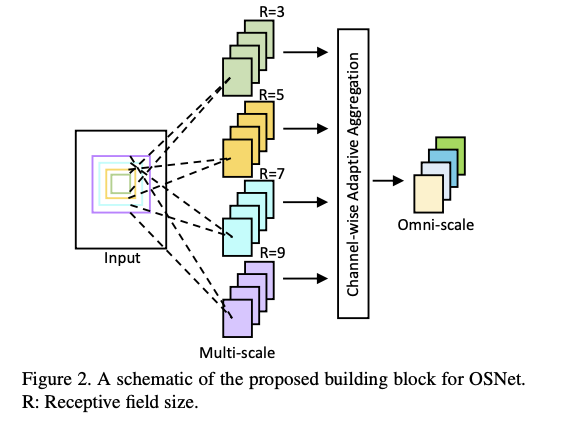
首先我們的模型要能夠提取出不同尺度的特徵,
這邊的做法是提取出 3, 5, 7, 9 的感知視野,
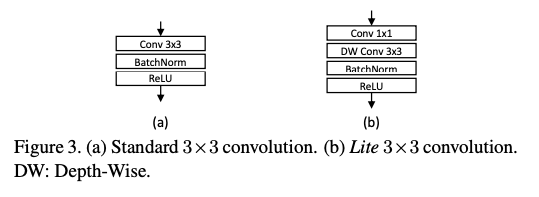
實際上程式碼的做法是使用 3x3 的 kernel 來達成,
舉例來說要達到 7x7 的感知視野就是 [3x3, 3x3, 3x3] 三個 3x3 做串連,
就 Inception 的概念,並且可以減少參數量達成輕量化模型。
提出 Aggregation Gate(AG)。
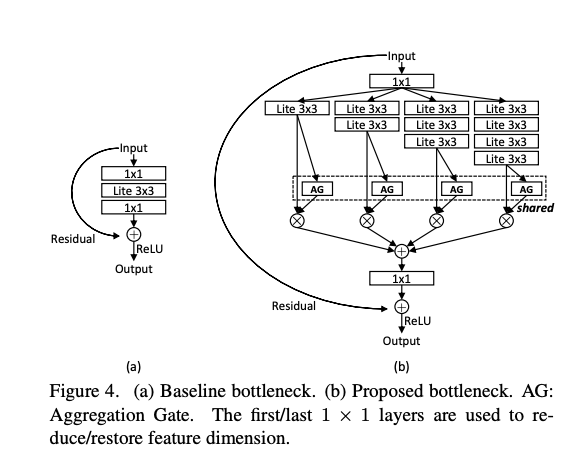
希望可以動態的混合這些不同尺度的特徵,
透過模型學習出目前要結合哪些尺度的特徵,
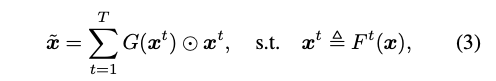
G 的架構 => Global average pooling -> MLP > ReLU -> FC ->Sigmoid
這邊有幾個比較特別的地方,
首先不同尺度的特徵,我們卻選擇使用同一個 AG,
這邊給出的概念是透過共享同一個 AG,
讓他們學會一起合作而不是各做各的。
除此之外採用 Residual 的概念,
它可以保留小尺度的特徵傳遞到下一層,
也可以混合不同尺度的特徵到下一層。
其他技巧就是使用 Depth-Wise 的網路架構來減少參數量。
成果