CACTUs簡介 - Unsupervised Learning via Meta-Learning
Kyle Hsu, Sergey Levine, Chelsea Finn. Unsupervised Learning via Meta-Learning. In ICLR’19.
ICLR 2019 paper
Paper link: https://arxiv.org/abs/1810.02334
OpenReview link: https://openreview.net/forum?id=r1My6sR9tX
Project page: https://sites.google.com/view/unsupervised-via-meta
Github(Tensorflow): https://github.com/kylehkhsu/cactus-maml
這篇有非常多的實作細節,
有興趣的請去看論文,
這篇看著看著,
廣泛的實驗、討論,
真有科研的精神呢,
挺推薦大家去看看的。
簡介
此文針對 Meta-learning 任務提出使用 Unsupervised (非監督式)的方式進行訓練,
概念是透過 Clustering embedding 的方式來訓練模型,
其想法是每個 Clustering 的中心點都是代表著某個重要的特徵(Representation),
那我們是不是可以透過使用這種學習出來的特徵來做學習呢?
這時候再回想起 Meta-learning 的想法是希望透過看過很多的任務,
學習出如何快速的學習一個任務 - Learning to learn。
因此帶出了論文的想法,
首先透過 Clustering 分群,
再透過學習 Clustering 的特徵,
達成學習如何快速學習特徵。
透過這種方式我們可以不需要任何 label 的資料就進行訓練,
算是切中的近年來 Meta-learning 的痛點 - 需要大量標注的資料才能訓練。
提出的此 Clustering to automatically construct tasks for unsupervised meta-learning - CACTUs 的方法在多個任務達到了不錯的成績,
雖然離 Supervised 的方法準確度有一段距離,
但這篇論文還是挺有看的價值的,
整體想法相當清晰!!!
概念
透過 Unsupervised 的方式建立出大量的任務讓 Meta-learning 的框架作學習,
搭配 MAML 以及 Protonet 做當作 Meta-learning 的框架進行探討,
而此篇是著重在如何以 Unsupervised 的方式準備大量的 Task 供 Meta-learner 學習。
如果對 MAML 以及 Protonet 沒有基礎認知的話,
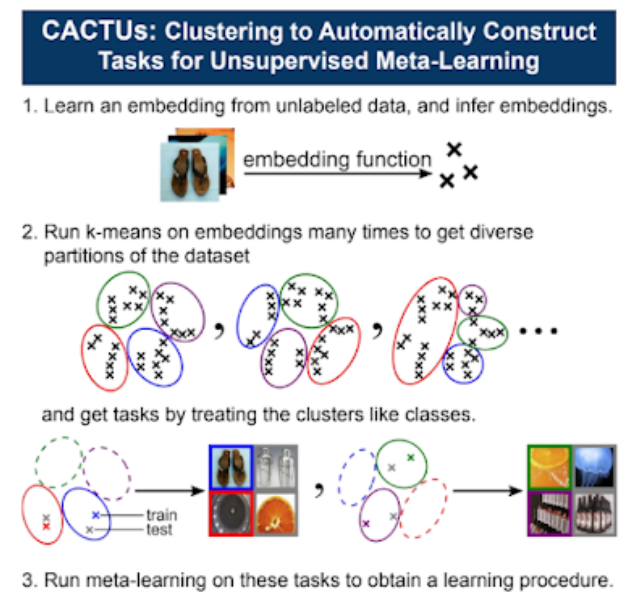
上圖是從 Project page: unsupervised-via-meta主頁的海報檔擷取的,我覺得這張圖比較好講解。
首先第一步是將資料集的圖片透過 Embedding function 將特徵(embedding) - Z 抽出,
之後會使用 K-means 的方式去將特徵進行分群,
這邊特別的地方是我們會對同樣的 embedding - Z 做多次的 K-means,
這樣子會拿到不同的群心,
也算是可以拿到更多的任務集,
這邊的想法是 K-means 的每個群心都有各自突出的特徵,
而我們 Meta-learning 的模型就是希望可以學習出如何快速學出這些特徵。
方法
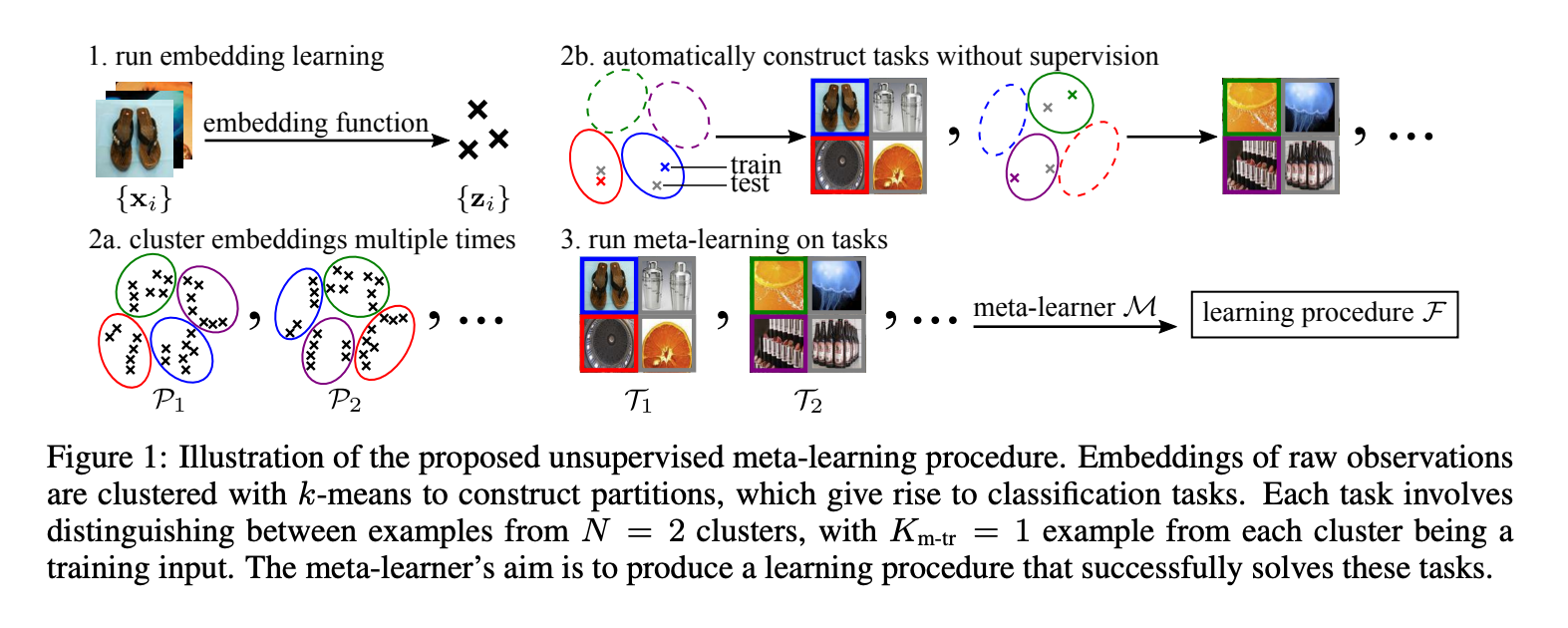
這篇其實挺抽象的,有興趣的去看程式碼。
 Line2 先訓練 Embedding function 再將資料集 X 進行 embedding 的抽取 - z
Line2 先訓練 Embedding function 再將資料集 X 進行 embedding 的抽取 - z
Line3: 跑 P 次 k-means,這邊跑 P 次可以看作是大量的抽取任務當作 Regularization 防止 Overfitting。
Note: 在 Omniglot 的實驗中, k = 500, P = 100。
Line5、6: 從眾多 P 挑一個,在從那一個挑 N 個類別。
Note: N 通常會和 Evaluation 的任務一致,舉例來說 20-way, 5 shot。 N 會挑 20。
Line7: 抽取 R 個 z 當作每個任務的樣本, R = Km-tr(Support 樣本) + Q(Query 樣本)。
這是 Meta-learning 常見的設定。

上圖是使用 DeepCluster-embedding 的展示,
此處的 Embedding function 論文採取了不同的方法進行探討,
這邊有興趣的去看論文。
討論
我抽幾點我覺得有趣的探討,
- 作者認為 Unsupervised 以及 Supervised 的準確度落差會一直存在,
因為最終我們所評測的任務都是一些高階的任務像是分類、辨識等等的,
並非我們使用 Unsupervised 所分出來的特徵,
可能這特徵相較之下還是過於簡單。
- 在 CelebA 資料集中的實驗結果中,
可以看到即便是在類別不平均的資料集,
該方法還是有不錯的成績。
之所以這樣說是因為在以往的 Meta-learning 實驗中的主流的資料集為 MNIST、Omniglot、miniImageNet,
上述的這些都是類別數平衡的資料集。
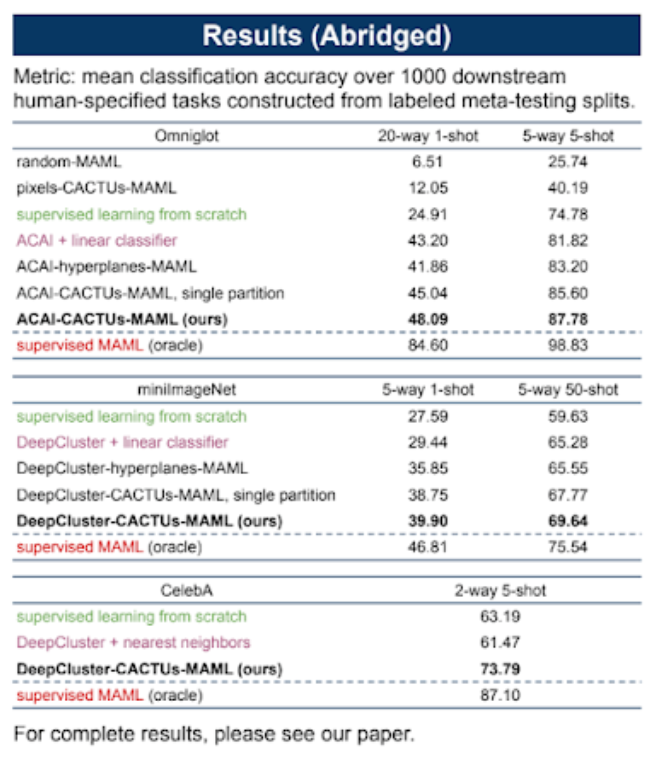
實驗:
因為太過於廣泛還有一堆細節,
我就不提了,
這篇如果對 Meta-learning 有興趣的人,
可以自己去深入研究。
Oracle 指的是使用 Supervised-learning 的結果,
可以發現其實 Supervised-learning 的結果好。