IBN-Net簡介 - Two at Once Enhancing Learning and Generalization Capacities via IBN-Net
Xingang Pan, Ping Luo, Jianping Shi, Xiaoou Tang. Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net. In ECCV’18.
ECCV 2018 paper
Paper link: https://arxiv.org/abs/1807.09441
Github(Pytorch): https://github.com/XingangPan/IBN-Net
簡介
作者認為現存的 CNN 模型能在單一個 Domain 取得好的成績,
但當它轉移到另一個 Domain 的時候,
可能因為外觀、光線等等的變化造成模型的準確度下降。
下圖可看出 Cityscapes 以及 GTA5 兩個資料集都是道路場景的語意分割資料集,

但是他們的外觀、光線、亮度都差得非常多,這邊稱作 Domain-shift,
這問題會導致訓練在 GTA5 的模型要套用至 Cityscapes 的圖片時準確度會下降。
Note: 因此也衍伸了 Domain adaptation 的任務研究。
此論文提出透過 IN (Instance-Normalization) 來讓模型可以適應不同的外觀,
讓模型能在不同外觀、 Domain 都能有著較好的通用性。
而此論文另一個探討就是如何讓 IN 結合常見的 BN(Batch Normalization),
因為現今的模型都是使用 BN 做加速收斂、學習出具鑑別的特徵。
提出了 IBN-Net - IN 結合 BN,
針對如何結合 IN 與 BN 給出一系列的探討,
能輕易的將這想法結合進現存的模型。
此篇任務以 ResNet 作為比較,
準確度上升並且套用至多個 Domain 進行測試,
能發現相較於 Resnet, IBN-net 較能夠適應不同的 Domain。
概念
其核心想法是希望模型對外觀變化(光線、色調等等的)不要這麼的敏感,
但同時我們還是希望模型可以學會如何辨識圖片的特徵,
這邊的想法是透過 IN 捕捉圖片中的低等特徵(亮度、顏色)-風格(Style),
並希望我們的模型能移除外觀上的變化,
達成外觀不變性(Appearance invariance),
再透過常見的 BN 加速收斂並學習出有用的特徵-內容(Content)。
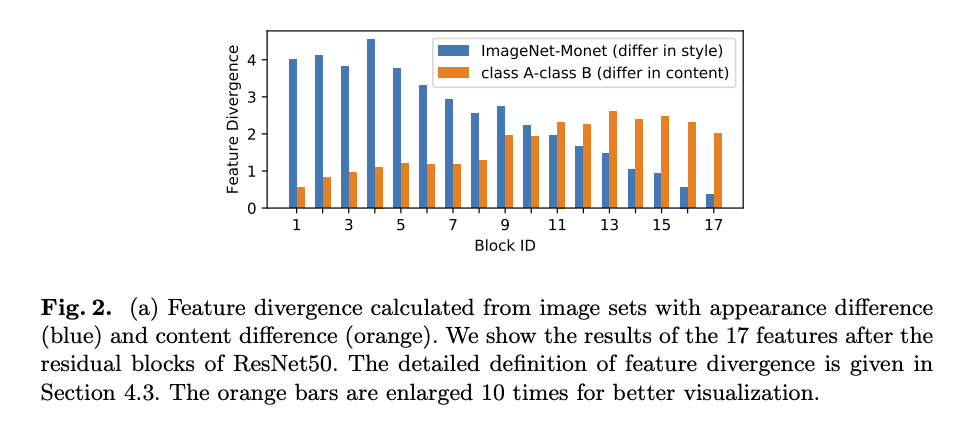
上圖簡單來說 x 軸代表著模型的深淺,
而 y 軸就代表著差異性,這邊使用 KL-divergence。
而藍色代表的是畫風所帶來的影響,
橘色代表的是圖片特徵所帶來的影響。
我們會發現外觀的差異在模型的淺層是較為明顯的 - Style,
而圖片的特徵則是模型的深層較為明顯 - Content,
透過這種觀察認為 IN 應該被用在模型的淺層,
而 BN 應該被應用在模型的深層。
架構
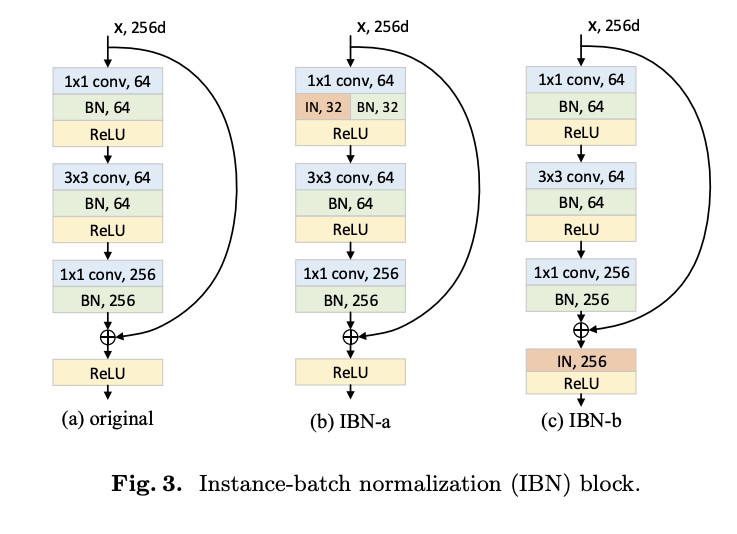
主要提出 a, b 兩種變形,
有幾個設計的原則:
- 在模型的深層往往學到的是內容,因此不要將 IN 放在模型的深層。
- 但在淺層的時候也會有可辨別特徵需要保留,因此在淺層仍要使用 BN。
IBN-a 架構
設計考量
- 架構應該要放在 Residual block,不然會破壞 ResNet 的設計原則,Identity path 不應該做改動。
IBN-b 架構
設計考量
- 不管是 Identity path 以及 Residual path 都會有外觀的資訊,因此將 IN 的架構放在相加之後,但為了不要破壞 ResNet 原本的想法,因此這個 IN 只會套用在 conv_1 以及前 2 個 Groups(conv_2, conv_3),較為淺層的 Layer。
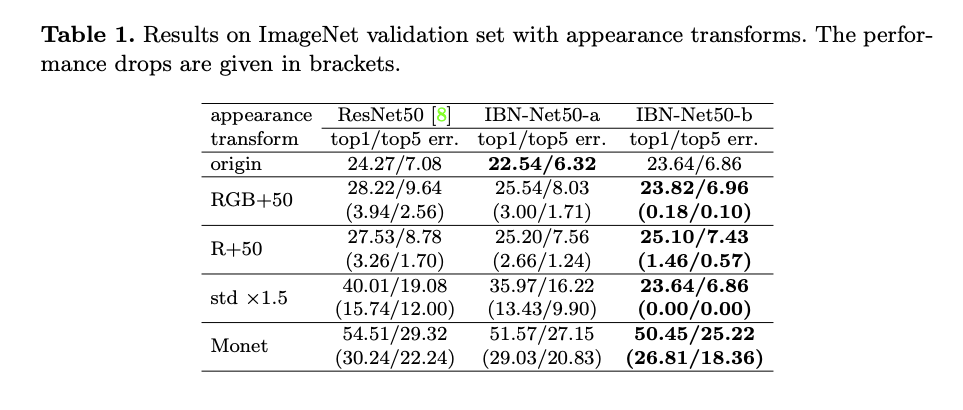
從下方實驗結果可發現:
當訓練在原本的 Domain 時 IBN-Net50-a 可取得好的成績,
當要應用至其他 Domain 的時候都是 IBN-Net50-b 取得好的成績。
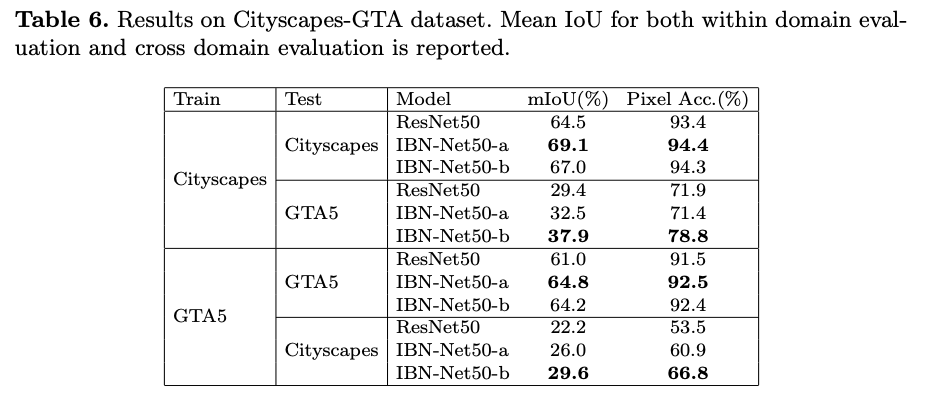
也可以將此模型套用至 Domain adaptation 的任務。
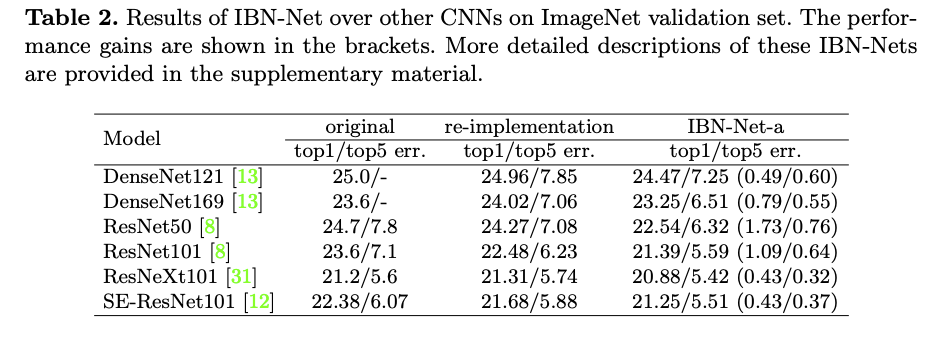
實驗結果
將 IBN-block 結合進近年主流的模型,會發現成績都有上升。
參考資料:
Two at Once: Enhancing Learning and Generalization Capacities via IBN-Net