簡介 - Regularizing Deep Networks by Modeling and Predicting Label Structure
Mohammadreza Mostajabi, Michael Maire, Gregory Shakhnarovich. Regularizing Deep Networks by Modeling and Predicting Label Structure. In CVPR’18.
CVPR 2018 paper
Paper link: https://arxiv.org/abs/1804.02009
簡介
作者提出了新的 Regularization 方式來增進監督式學習的成效,
其概念是希望模型可以更好地理解圖片中內容(Context)的關聯性。
提出藉由 Autoencoder 的架構,
學習出各個 Channel 之間的關聯性,
因 Autoencoder 是利用 Encoder 將資料壓縮之後再將壓縮過的資料經由 Decoder 還原,
在壓縮資料(1x1 convolution 做維度縮減)時,
其實可以看作是學習不同特徵/內容間的相關性。
因此本文提出在訓練監督式學習的主要模型時,
可以搭配 Autoencoder 的做訓練,
希望它能夠學會 Autoencoder 所學會的內容之間的關聯性,
實驗結果顯現此方式可提升監督式學習的準確度,
方法
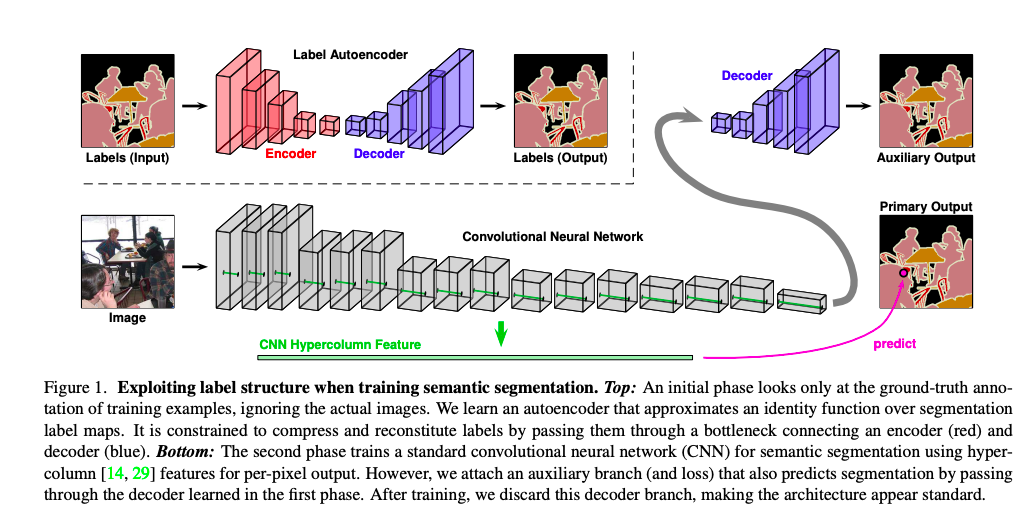
Step1.(圖片上半部)首先我們會訓練 Autoencoder 架構,
輸入圖片輸出語意分割(Semantic segmentation)的結果,
將 Autoencoder 訓練至收斂後,我們就凍結(Freeze) Autoencoder 的權重。
Step2.(圖片下半部)透過監督式學習結合 Autoencoder 架構所訓練的解碼器(Decoder)進行訓練,
將主要模型的特徵輸入至解碼器,希望他經由解碼後能夠輸出 Semantic segmentation 的結果。
- Crossentropy Loss(Primary, GT)
- MSE Loss(Primary, Auxiliary) - 針對 Semantic segmentation 的輸出
替代方法
利用 Encoder 的部分,達到原先方法相似的成效,後續實驗結果表明,使用 Decoder 結果較好,並且使用 Decoder 可解釋性較佳,畢竟使用 Encoder 壓縮過後的資料,比較沒辦法可視化。
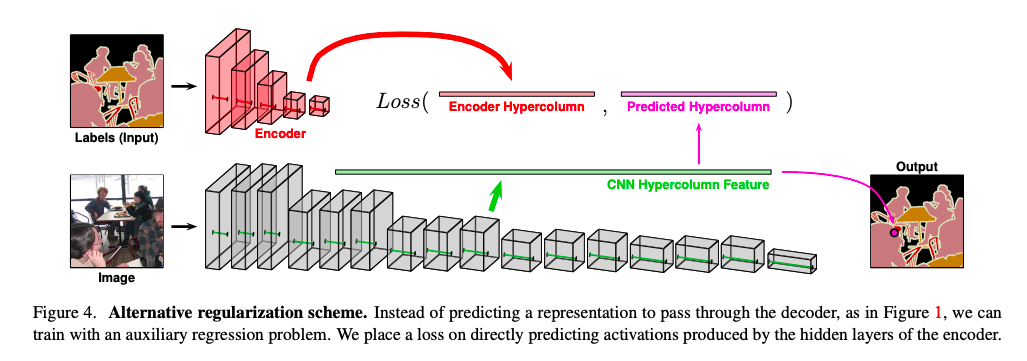
Step1.(圖片上半部)首先我們會訓練 Autoencoder 架構,
輸入圖片輸出語意分割(Semantic segmentation)的結果,
將 Autoencoder 訓練至收斂後,我們就凍結(Freeze) Autoencoder 的權重。
Step2.(圖片下半部)透過監督式學習結合 Autoencoder 架構所訓練的編碼器(Encoder)進行訓練。
- Crossentropy Loss(Primary, GT)
- MSE Loss(Primary, Auxiliary) - 針對 Feature map 做比對
實驗結果
下方實驗的 hypercolumn 可忽略,那是其他論文所提出的架構。
從下表可看出,使用本文所提出的方法 - 搭配 Autoencoder 的 Decoder 一起做訓練,結果有顯著的提升。 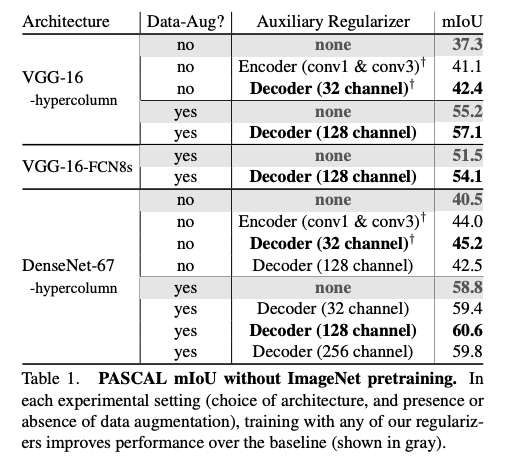
下表第二列是使用本文的分兩階段(Freeze Autoencoder 權重)做訓練 - 60.6
第三列則顯示分兩階段但是不 Freeze Autoencoder 權重做訓練 - 60.2,與第二列比較代表了並不是越多分支一起訓練就會好,還是要有策略地去訓練。
第四列則顯示不分階段,兩個階段一起(joint)做訓練 - 58.8 
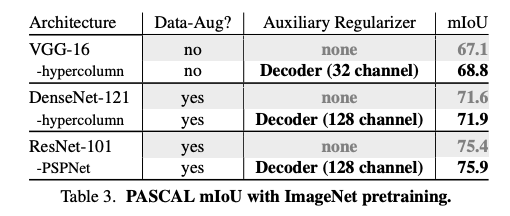
嘗試使用不同架構來驗證此方法有效,可以看到當使用較複雜的模型時 Resnet-101 + PSPNet,其實增加的幅度有限。

參考資料:
Regularizing Deep Networks by Modeling and Predicting Label Structure