Anchor Tasks 簡介 - Anchor Tasks Inexpensive, Shared, and Aligned Tasks for Domain Adaptation
Zhizhong Li, Linjie Luo, Sergey Tulyakov, Qieyun Dai, Derek Hoiem. Anchor Tasks: Inexpensive, Shared, and Aligned Tasks for Domain Adaptation. In ArXiv preprint.
ArXiv preprint, Submitted on 16 Aug 2019.
Paper link: https://arxiv.org/abs/1908.06079
Github: 尚未釋出,可關注作者的 Github。
https://github.com/lizhitwo?tab=repositories
簡介
作者提出了新的 DA(Domain adaptation) 的方法,
其概念是某些任務的 Pixel-level 的標註(Annotation)難以取得的時候,
我們可以使用相似任務(Anchor task)的標註來進行 DA。
此篇是基於以往 DA 的構想延伸,
DA 是因為現實資料集的標注取得不易,
因此會使用合成資料集的標注去做訓練,
而此篇多使用了一個 Anchor(輔助任務)的資料集進行訓練,
因作者認為合成的資料集往往會有不同種類的標註(Annotation),
e.g., Facial landmarks, Bounding box, Semantic segmentation,
因此多使用一種標註資料做訓練是可行的設定。
因以往 DA 任務中 Target domain 都是只給定輸入圖片(Xt),
做完 DA 後結果往往還是過於粗糙,
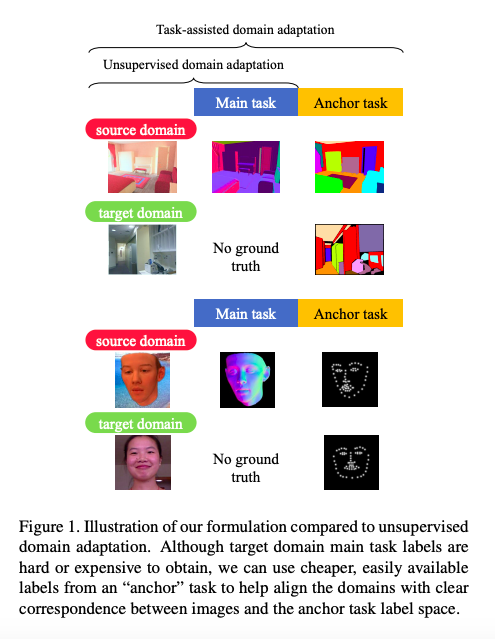
但現在 Target domain 不只給定圖片還給定了 Anchor task 的標註(Xt, Yt_anchor),
再加上此方法的 Main task 以及 Anchor task 是使用同一張輸入圖片,
因此 DA 可以藉此學會兩任務間空間資訊的關係(Spatial alignment),
當 Main task 和 Anchor task 的空間資訊對齊後,
再透過 Source 以及 Target 的 Anchor task 進行 DA。
此論文使用兩階段的訓練,
藉由凍結(Freeze) CNN 後半部的 Layer 可更有效的利用 Feature 的空間資訊。
Note: 此論文主要是探討 Pixel-level 的任務。(Facial landmarks, semantic segmentation)
DA 方法差別 - 針對資料集差異
先簡單介紹一下原本的 DA 資料集設定
針對 A 任務做 DA
- Source domain: 通常是合成資料集(Xs, Ys) - 取得容易
- Target domain: 通常是現實資料集(Xt) - 認為人工標注資料耗時間、金錢,因此不會給定 GT。
此論文的 Anchor task 設定
算是 Multi-task 的變形,
針對 A 任務做 DA 但還使用了 B 任務做輔助。
- Source domain: A 任務合成資料集(Xs, YAs, YBs) - 取得容易
- Target domain: 通常是現實資料集(Xt, None, YBt) - 對 A 任務來說,人工標注資料耗時間、金錢,因此不會給定 GT,但是相較於 A 任務來說,B 任務的標注成本還算可以接受,如果準確度能提升的話那就標吧。
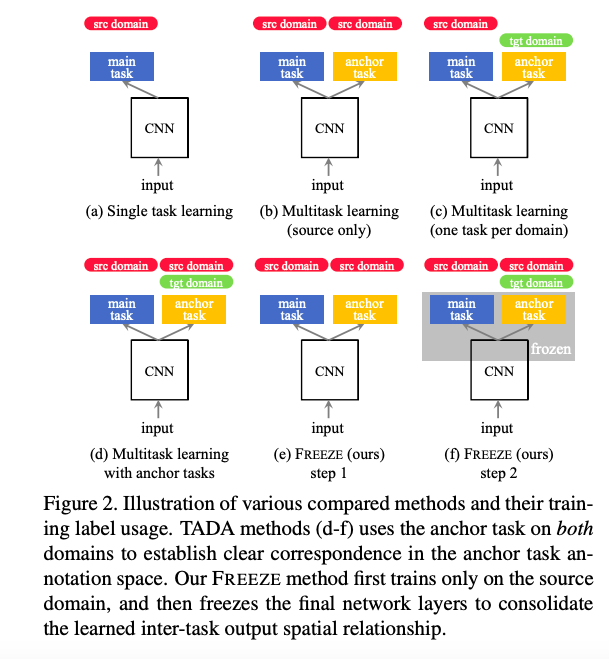
下面這張圖 - fig2. 就自己看吧,介紹不同資料集設定下的不同的名稱。
方法
主要方法是基於 Task-assisted Domain Adaptation 作延伸,
最簡單的方法是對於各個任務都進行 Supervised 的學習,
就是 Multi-task Learning (MTL)的方式:
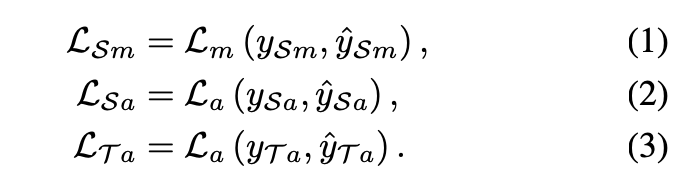
比較各種方法:
- MTL-src 使用 Source domain Main 以及 Anchor Task
- MTL-SmTa 使用 Src 的 Main Task 以及 Tgt 的 Anchor Task
- MTL-a 使用 Src 的 Main Task, Anchor Task, 以及 Tgt 的 Anchor Task
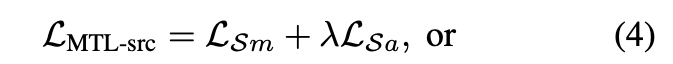
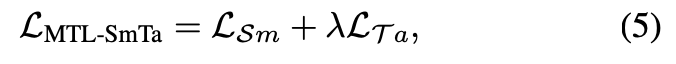
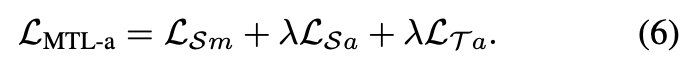
FREEZE
可當作兩步驟的訓練,
想法與 CVPR’18 Regularizing Deep Networks by Modeling and Predicting Label Structure 相似,
可以將最後幾層的 CNN 當作是 Decoder,
他其實是學習將 Backbone 的特徵映射到這兩個任務的 Output space(Joint label space of the two tasks)。
因此使用了 Regularizing Deep Networks by Modeling and Predicting Label Structure 相似的技法 - 2-Phase Training,
首先會先訓練 Source domain 的 Main 以及 Anchor 至收斂,
接著將後面幾層(可看 fig2. - 包含 CNN 後半以及 Output/Classifier layer)凍結(Freeze),
接著透過下方式子只訓練淺層的特徵 - 對 Feature space 做 DA 的概念。
可結合以往的 GAN-based DA
此外此方法也可結合 Tsai et al., AdaptSegNet 或是 Unsupervised domain adaptation by backpropagation 的 DA 方法。
Note: 這部分請慎用,其實結合 GAN-based 的方法要調很多參數,而且也不見得比較好,可看此論文的補充。
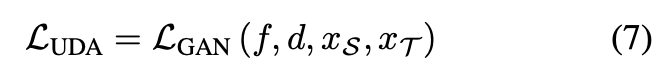
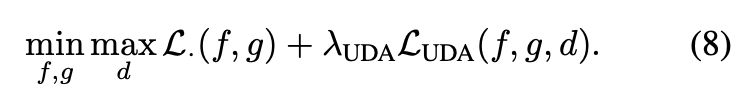
實驗結果
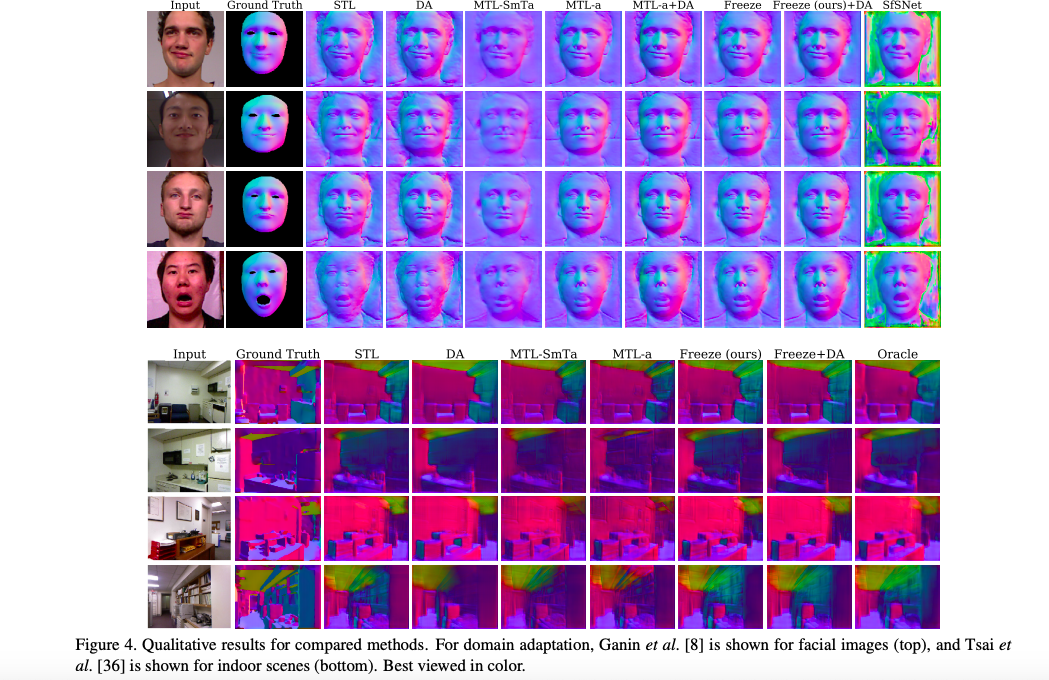
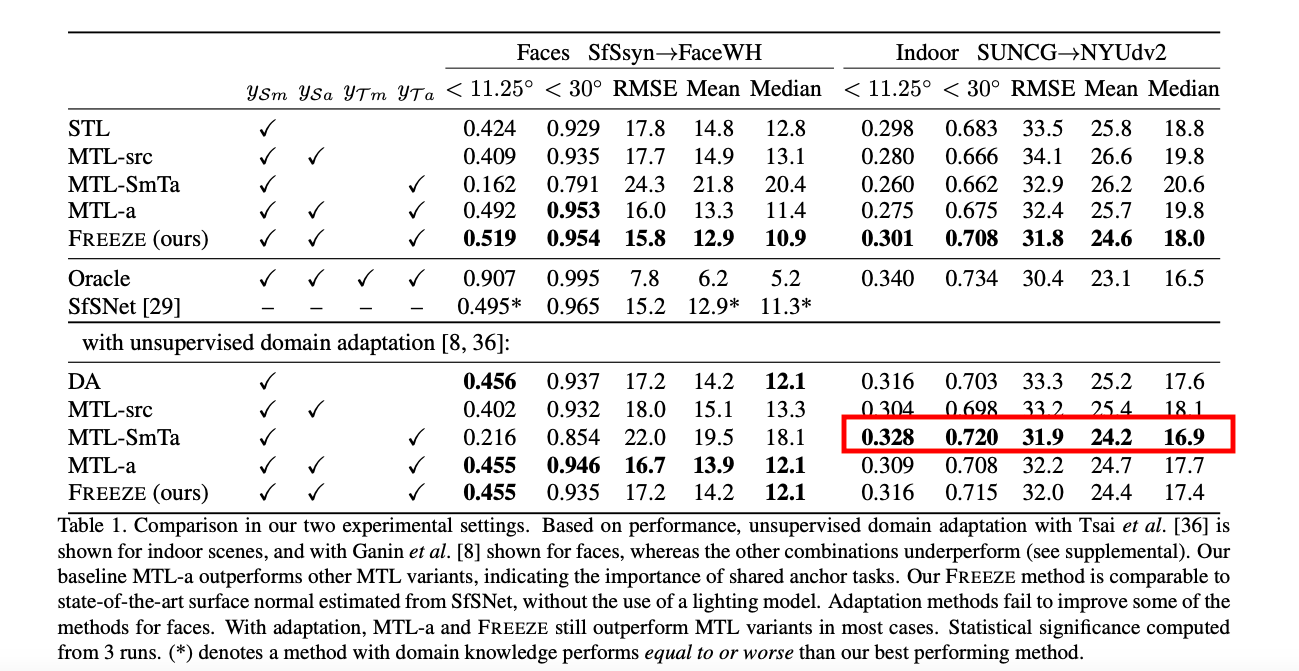
至於為什麼在 Indoor SUNCG→NYUdv2 搭配 DA 的實驗中,
MTL-SmTa 竟然會最高呢?這邊論文說是因為 GAN-based DA 的不穩定性,
摁… 其實做過 GAN-based DA 大概就能理解這本身就不是很穩定。。。
但這也是直得探究的議題,
只是這篇論文沒探究,
它轉為述說就算如此在 DA 的部分 MTL-a 結合 Freeze 還是比單純 MTL-a 好。
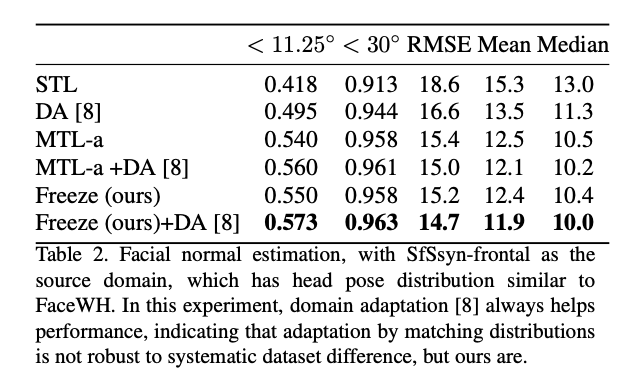
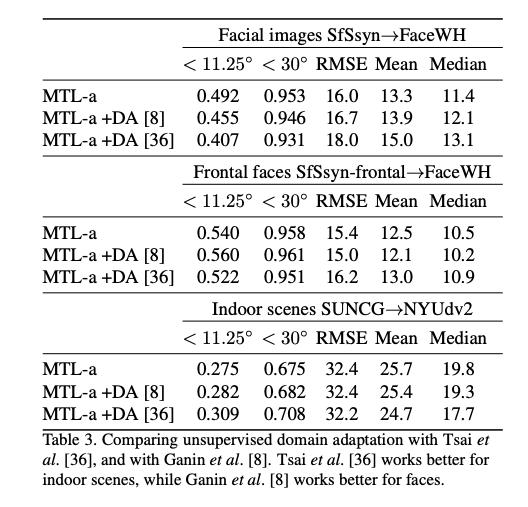
參考資料:
Anchor Tasks: Inexpensive, Shared, and Aligned Tasks for Domain Adaptation
Regularizing Deep Networks by Modeling and Predicting Label Structure