Tf-KD 簡介 - Revisit Knowledge Distillation a Teacher-free Framework
Li Yuan, Francis E.H.Tay, Guilin Li, Tao Wang, Jiashi Feng. Revisit Knowledge Distillation: a Teacher-free Framework. In ArXiv preprint.
ArXiv preprint, Submitted on 25 Sep 2019.
Paper link: https://arxiv.org/abs/1909.11723
Github(Pytorch): https://github.com/yuanli2333/Teacher-free-Knowledge-Distillation
簡介
本文對於 Knowledge Distillation(KD) 進行一些實驗,
以往 KD 是使用較為複雜的模型(Teacher)去訓練較為簡單的模型(Student),
其想法是希望 Student 可以去擬合 Teacher 的各個類別的預測機率,
藉此學得比原本只使用 Supervised 訓練的方式來的更好。
而本文提出兩個有趣的實驗
- 若使用 Student 來訓練 Teacher,這樣 Teacher 是否會改善 => Teacher 會變好
- 若使用很爛的 Teacher 來訓練 Student,這樣 Student 是否會改善 => Student 會變好
Teacher 準確度約為 10%。
這兩個結果都讓人意外。
作者對於實驗結果探討並解釋 KD 是一種 Label smoothing regularization(LSR) 的變形,
並探討 KD 與 LSR 之間的關聯性,
認為 KD 其實也是一種 Regularization。
本文藉由上述的結果提出 2 種 Teacher free distillation(Tf-KD) 的方法來增進模型效能,
而 Teacher free 的應用場景可以針對本身就已經是很龐大的模型(Resnet-101)進行優化,
如果照著以往 Teacher-student 的訓練方式的話,
我們的 Student 已經是很龐大的模型了 - Resnet 101,
這時候若在找一個更龐大的 Teacher 模型,事實上是有難度的。
透過此方法在 ImageNet 資料集提升了 0.65 %,且此方法優於 LSR。
實驗探討
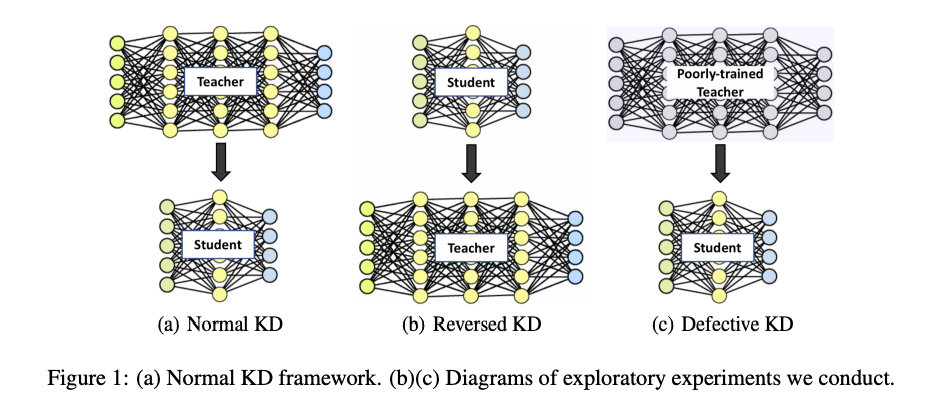
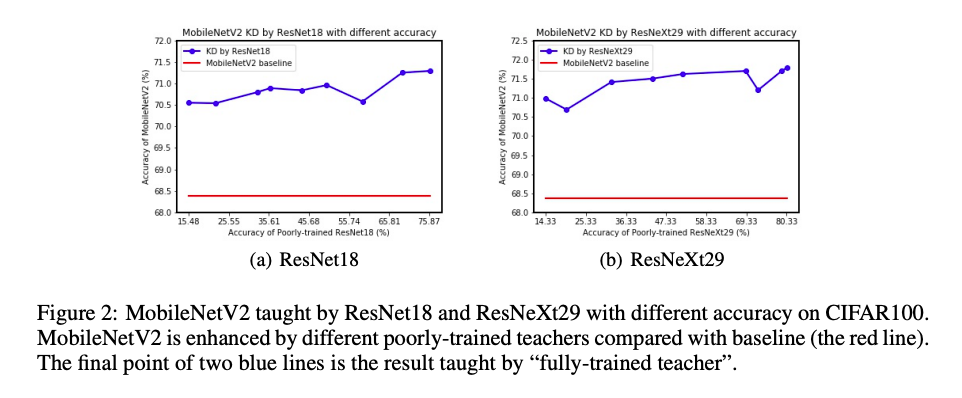
上面兩張圖是表達相同的事情
- Normal KD:以往 Teacher-Student 的設定,會有個較為龐大並且準確度高的模型(Teacher)去教較為輕量且準確度中上的模型(Student),期望可以藉由 Teacher 將 Student 的準確度再往上提升一點。
- Reversed KD(Re-KD):使用較為輕量且準確度中上的模型(Student)去教導較為龐大並且準確度高的模型(Teacher),實驗1。
- Defective KD(De-KD):使用較為龐大並且準確度極差(10%)的模型(Teacher)去教導較為輕量且準確度中上的模型(Student),實驗2。
照邏輯來看經過 Reversed KD 以及 Defective KD 訓練後,
準確度應該會變低,
但是實驗的結果卻是相反。
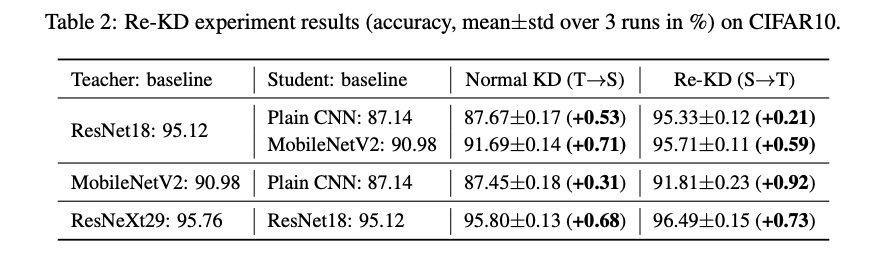
Reversed KD(Re-KD)
透過 Student 來教導 Teacher,
竟然出乎意料的改善了 Teacher 的準確度!!

Defective KD(De-KD)
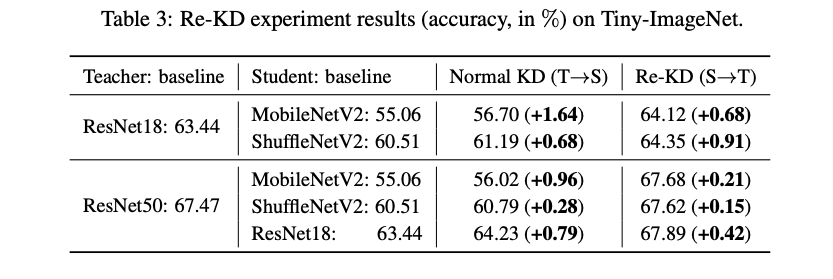
透過比 Student 還爛很多的 Teacher 來教導 Student,
竟然也出乎意料的改善了 Student 的準確度!!
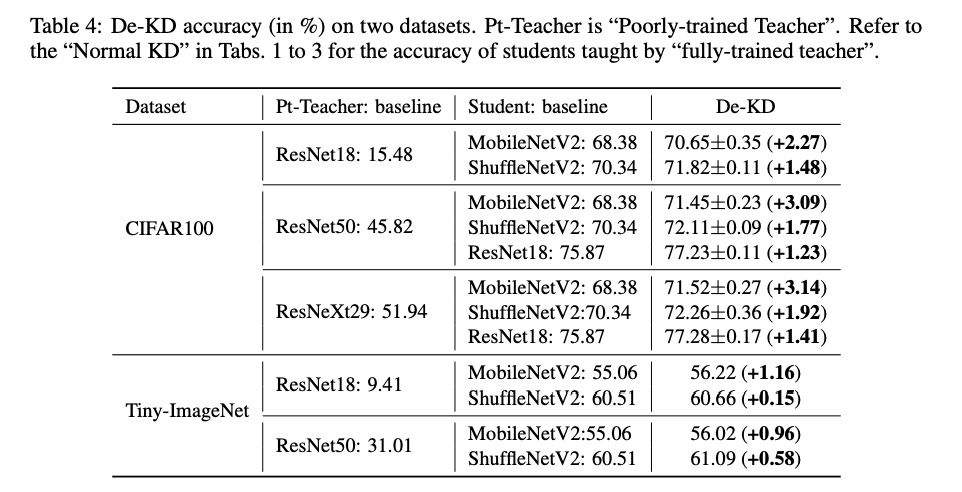
我們可以看到下圖,
紅線為 Baseline,即為單純使用該 Model 進行 Supervised 訓練的準確度,
x 軸為 Poor teacher 的準確度,
y 軸為透過 Poor teacher 進行 De-KD 所獲得的準確度,
可以發現不管 Poor teacher 多爛都還是會比原本只使用 Supervised 的方式好。
基於上方兩個實驗,
作者推測 KD 其實是一種 Regularization,
並且加以解釋它與 Label smoothing regularization(LSR) 的關係。
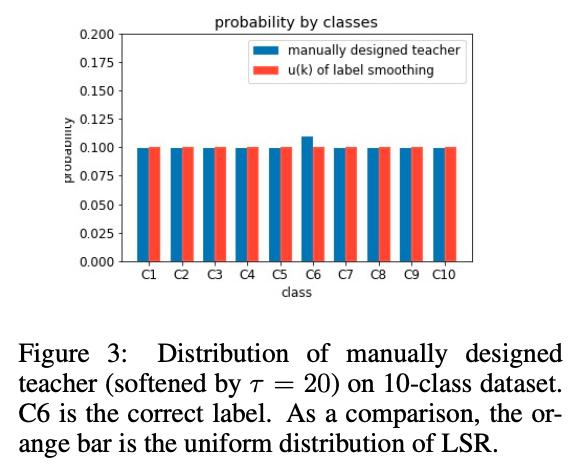
LSR:
u 通常為 1/K(類別數) 的常數。
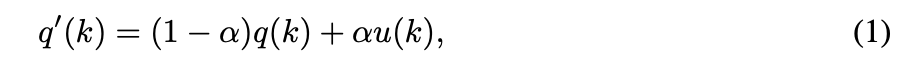
對於下面這步驟不知道怎麼從 Cross-entropy 轉換成 KL-divergence 的可以看 Cross Entropy, KL Divergence, and Maximum Likelihood Estimation
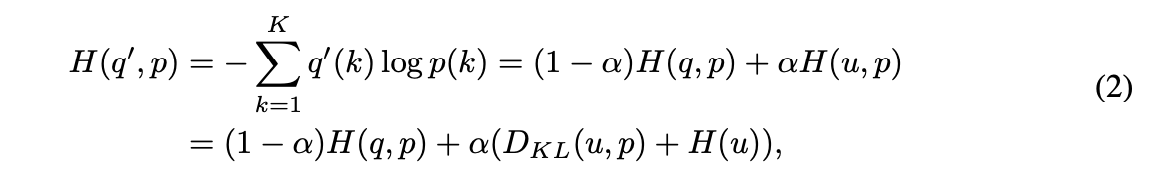
那因為 H(u) 的 u 為常數,因此我們可以將式子簡化成下方這樣。
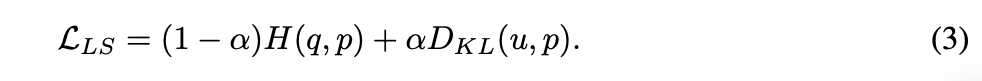
而 KD 的想法是針對 Teacher 以及 Student 的各個類別的輸出機率進行 KL-divergence,
希望他們越相近越好。
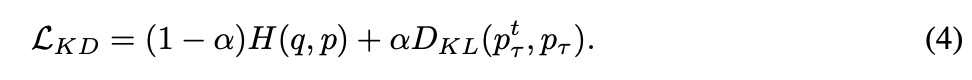
所以這邊這樣一看,還真有點像啊~
只是 LSR 是使用了常數 u 當作 Regularization,
而 KD 是使用了 Teacher 模型的預測機率,
希望兩個模型的輸出類別機率要相像(Similarity between categories),
因此作者認為 KD 是一種可學習的 LSR 方法,而 LSR 則是一種特殊形式的 KD。
以及針對 KD 給了這番解釋:
Dark knowledge does not just include the similarity between categories, but also imposes regularization on the student training.
上方有興趣的自己去看論文,其實還有一些細節沒詳述。
方法
基於上面 Reversed KD 以及 Defective KD 的實驗,
作者推測不可靠的模型或是 T 和 S 間的類別相似度完全不同的情況下,
KD 都還是會改善模型準確度。
作者並提出了兩個簡單的想法來實現 Teacher-free KD。
- Self-training
- Virtual teacher(100% 準確度)
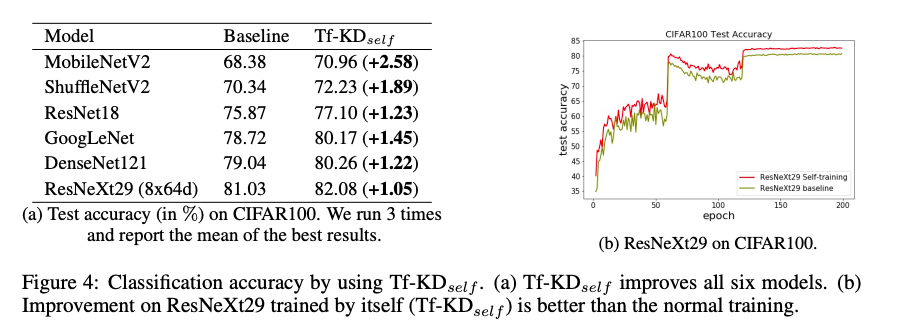
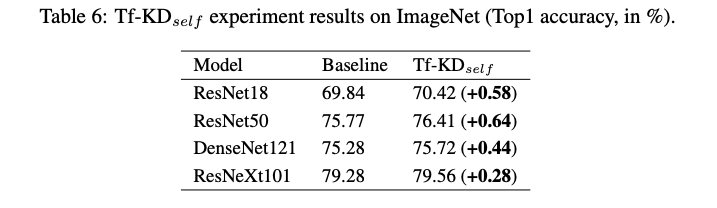
Self-training(Tf-KD_self)
首先我們會使用 Supervised 的方式訓練好一個模型 - Pretrained model,
把 Pretrained model 當作 Teacher => pt,
接著再透過 KD 的方式訓練,如下:
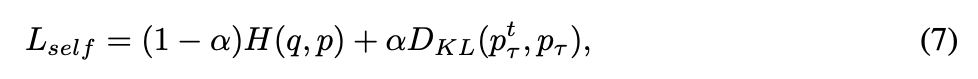
Virtual teacher(Tf-KD_reg)
這邊挺有趣的,
我們可以使用一個 100 % 準確度的 Teacher model,
因為是訓練資料,
所以我們會知道 GT,
因此我們可以結合 LSR 的方法,
確保正解 Yi 的類別機率永遠都是比其他類別高,
也是進行一個 Regularization 的概念。
式子就會長成這樣
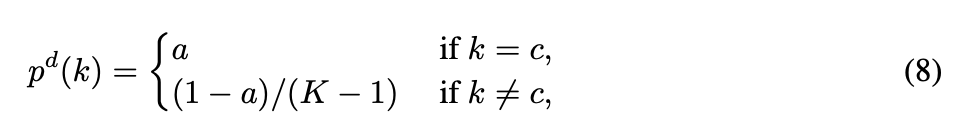
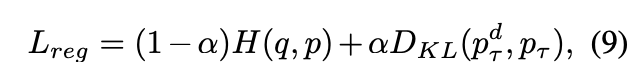
其他實驗
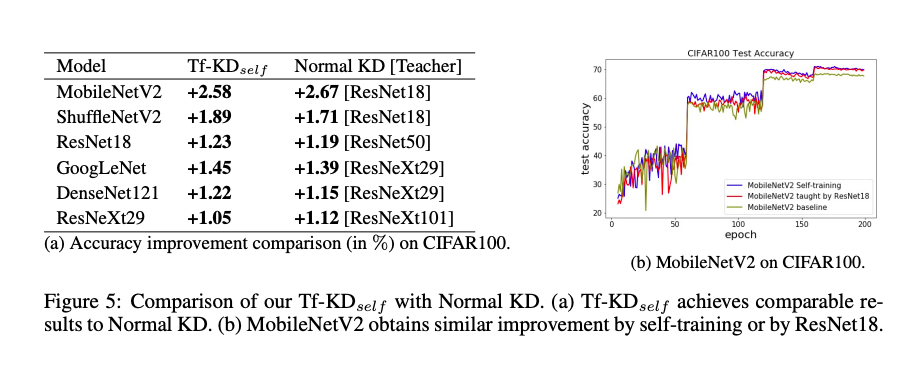
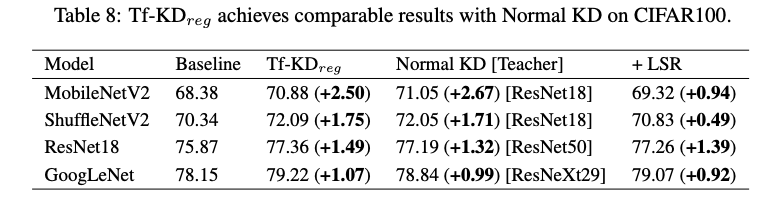
與 Baseline、正常的 KD 以及與 LSR 方法比較

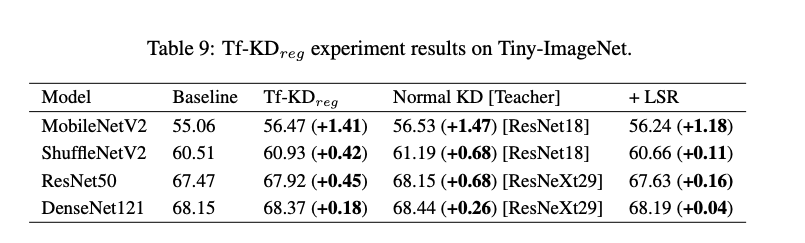
未來展望
現在都只是在 Image classification 做實驗,
對於其他更複雜的任務還需要確認它是否可行。
參考資料:
Revisit Knowledge Distillation: a Teacher-free Framework
Cross Entropy, KL Divergence, and Maximum Likelihood Estimation