Guided-pix2pix 簡介 - Guided Image-to-Image Translation with Bi-Directional Feature Transformation
Badour AlBahar, Jia-Bin Huang. Guided Image-to-Image Translation with Bi-Directional Feature Transformation. In ICCV’19.
ICCV 2019 paper
Paper link: https://arxiv.org/abs/1910.11328
Github: https://github.com/vt-vl-lab/Guided-pix2pix
簡介
作者提出了新的 Guided Image-to-image translation 的架構,
以往的圖像轉換 Image-to-image translation 最常見的就是斑馬換成馬,
但 Guided Image-to-image translation 是給定一個額外的資訊(顏色、深度、圖片、骨架等等)作為條件,
去生成出基於該資訊的圖像。
而以往的研究都是專注於某個任務,
而此模型可適用於不同的任務 Guided-pix2pix。

本文提出兩個貢獻
使用 Bi-directional Feature Transformation (bFT) 來達到更好的轉換效果。
提出 Spatially Varying 的 Feature-wise transformation。
Note: 這部分其實和 CVPR’19 SPADE - Semantic Image Synthesis with Spatially-Adaptive Normalization. 想法差不多,建議去看那篇。。。
方法
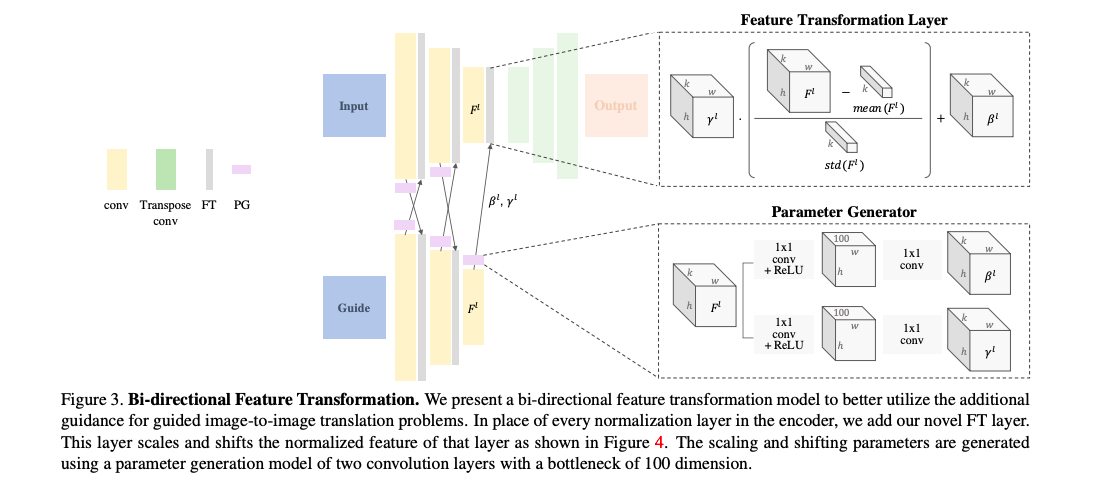
Bi-directional Feature Transformation (bFT)
我們先看看以往是如何進行 Guided Image-to-image Translation.
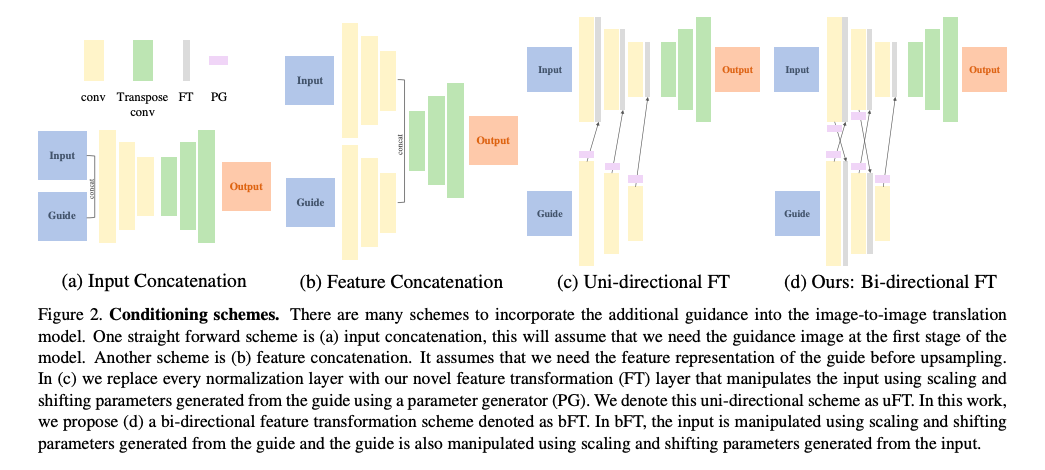
- 將 Input 的圖片與 Guide 的圖像做串接 - (a)
- 將 Input 的 Feature map 與 Guide 的 Feature map 做串接 - (b)
- 輸入 Guide 去預測參數 Scale 以及 Bias(Shift) 透過此參數去 Normalize Input 的 Feature map - (c)
Note: 預測參數的模型稱作 PG(Parameter generator) 紫色的圖例 AAAI’18 Feature-wise Linear Modulation(FiLM) 其實原文是用在 VQA 任務拉。。。
- 本文提出之 Bi-directional FT - (d)
不僅僅是透過 Guide 的參數去 Normalize 原本的圖片, 甚至是透過圖片所預測出的參數去 Normalize Guide 的部分, 這部分作者認為可以將此架構視為 Teacher - Student 的架構 以往都是 Teacher 單方面的教 Student, 因此嘗試透過這種互動的方式來達到更好的效能, Umm,這部份其實他沒做太多的探討, 有興趣的人可以研究看看。
Feature transformation layer
主要是與 Feature-wise Linear Modulation(FiLM) 做比較,
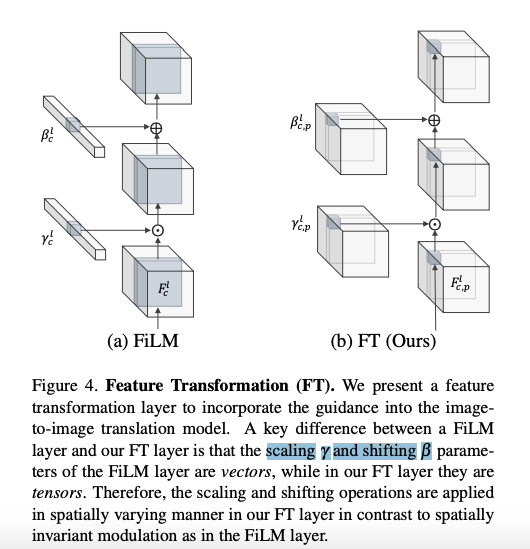
由上圖可以看到 FiLM 是預測出 Scaling γ 和 Shifting β 的參數(vector),
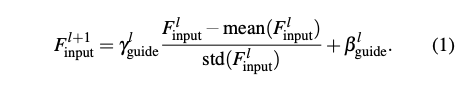
這意味著它是無法辨別出空間上的不同 - Spatial Invariant。
而這其實會喪失掉 Guide 的空間上的資訊,
以至於沒辦法達成很好的轉換效果,
因此這邊提出使用基於每個 Pixel 預測出 scaling γ 和 shifting β 的參數(Tensor),
說穿就是接個 Bottleneck 的 1x1 conv 作為輸出。
而這特性對於一些不同的 Guide (Dense, sparse, multi-channel)也是較有彈性的。
Note:
這邊其實去看 CVPR’19 SPADE - Semantic Image Synthesis with Spatially-Adaptive Normalization. 或許你會有不同的見解。
下方式子是將 Input 的 scaling γ 和 shifting β 傳遞給 Guide,此式和 eq1 相似,是本文 Bidirectional 的概念。
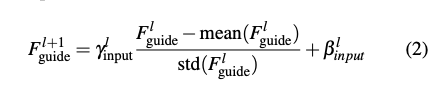
整體架構
實驗結果
細節數據比較我就不貼了,
有興趣自己去看論文。

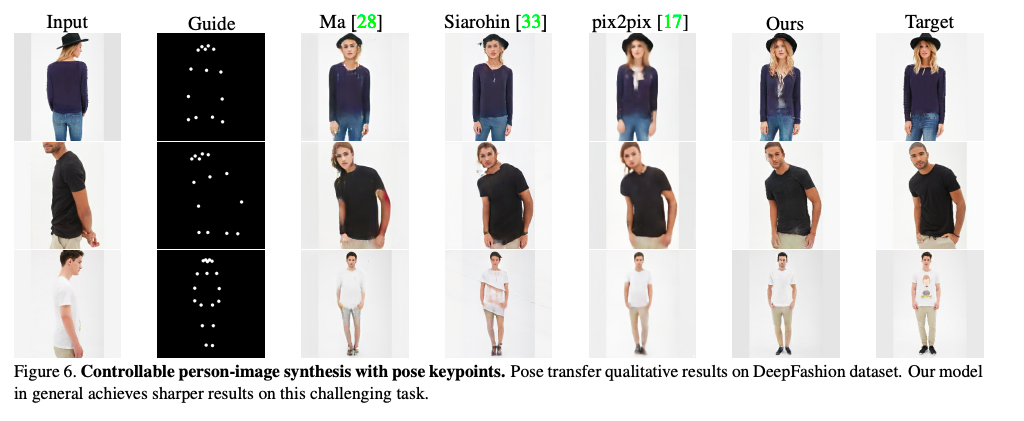

失敗的測資才是最值得研究的呢~

參考資料:
Guided Image-to-Image Translation with Bi-Directional Feature Transformation.
CVPR’19 SPADE - Semantic Image Synthesis with Spatially-Adaptive Normalization.