簡介 - Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation
Fabio Pizzati, Raoul de Charette, Michela Zaccaria, Pietro Cerri. Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation. In arXiv preprint.
Arxiv preprint, Submitted on 23 Oct 2019.
Paper link: https://arxiv.org/abs/1910.10563
Github: 2019.11.15 尚無。
簡介
作者基於現存的 Unsupervised Image-to-image translation 的架構進行改良,
首先提出現存的模型只會轉換全局的特徵,
以將晴天圖片轉換至雨天為例,
以往的模型會將整張圖片的色調調暗來表示雨天,
但對於一些雨天的細節特徵卻沒有做好(e.g., 車窗上的水滴)。
而本文提出可以利用網路上的資料來加強特定特徵的細節部分,
可獲得更為真實的圖片並將此用於訓練,
可達到 Domain bridge 的作用。
並近一步將此圖像轉換的方法用於 Unsupervised Domain Adaptation (UDA) 的任務,
在 UDA 著名的 GTA5 to Cityscapes 任務中也達到不錯的成績。
本文提出的貢獻為
- Image-to-Image:使用網路爬蟲(註1)獲得更多的相同類型資料,增加資料集的多樣性。此處本文的方法稱作 Domain Bridge。
- Image-to-Image with UDA:近年來 UDA 的趨勢是先採用 Image-to-Image 來緩解 Domain shift 的問題,但是他們往往因為記憶體考量,先將整個資料集做 Image-to-Image(將每張圖片都轉到 Target domain - 1 轉 1),而本文不同之處是在於使用了 Multimodal 的圖像轉換(註2),因此可在訓練過程中將同一張圖片隨機生成不同樣式的圖片(1 轉 N),可當作數據增強。此處本文提出方法為 Online Multimodal Style-sampling(OMS)。
- UDA:提出新的 Self-supervision 的策略,基本上概念就是 Self-training,如果 Target Domain 的分類出來的信心水準高的話,我們可以把它當作是 GT 改為使用 Supervised 的訓練。此處本文提出方法為 Weighted Pseudo-Labels(WPL)。
Note:
- 註1: 在本文中雖說藉由 Web Crawler 網路爬蟲增加資料,但是實驗是用較簡單的方式,將 Youtube 中的 5 部影片作為額外的訓練,與想像中的的 Online learning 有所不同。這邊也給定較為嚴格的條件:要從特定頻道去抓影片以避免每抓一部影片就多一個 Domain。
- 註2: Multimodal 的架構是採用 ECCV’18 MUNIT-Multimodal Unsupervised Image-to-Image Translation


方法
Domain Bridge
以 Image-to-Image 的模型來說,
有一個常見概念是 Latent space,
代表這兩張圖片可能有某些特徵是共享的,
舉例來說要做狗和貓的圖像轉換,
那他們之間的 Latent space 可能是眼睛、鼻子、嘴巴。
這邊以 ECCV’18 MUNIT-Multimodal Unsupervised Image-to-Image Translation 的圖片做介紹。

因此我們可以將這些 Latent space 分為我們有興趣的天氣 Weather(W) 相關與其他無關的 Others(O)。
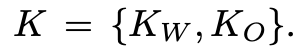
備註:原文的講解是 K 為 Fine-grained domains,但我改用 Latent space 做解說。
將乾淨的圖片(X)以及下雨的圖片(Y)各自擁有的 Latent space 定義如下:
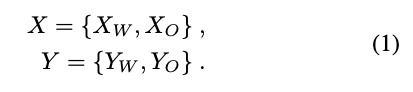
基於 Image-to-Image 的模型穩定學習,
有辦法正確的轉換圖片至我們要的效果(乾淨 <=> 下雨),
代表著模型可以學會各自資料集(X, Y)的主要不同(此處為天氣 W),
這時候模型是不斷地朝著要變的更像另一個資料集,
說起來是好,但這樣子我們再看一下我們剛剛定義的 K。
在這種情況下,可能對於天氣的因素 Kw 已經學得很好了,
再接下來他學的都是 Ko 去擬合你手上現有的兩個資料集(X, Y),
而這些可能不是我們最關心的,
如道路、車子的細節之類的。
因此提出我們可以基於天氣的條件,
去獲得一些外部的資料源(此處是 Youtube 的影片) - Z,
本文給定較為嚴格的條件,去抓了 5 部影片下來。 好天氣、正常的雨、大雨。
藉由此資料源來讓我們可以再多學到一點 Kw 天氣的因素,
這邊所給定的假設是當我們新增的外部資料源,
在這些新給定的樣本是在”某些篩選條件”之下,
在此設定之下對於多數的特徵 Ko 會獲得更多相似的樣本,
這使得 KL-Divergence(Pxo, Pyo) 變小,
但是對於 Kw 來說它經由新給定的樣本還是面臨著挑戰(乾淨的圖片以及下雨),
甚至是原文的設定不只找下雨的影片、還找了下大雨的影片。
這時候模型就會專注在 Kw 的部分學習,
學會 Kw 中的一些細節,如水滴等等。
其實這也是這篇論文有點讓人困惑的部分, 要有前提的去選擇樣本, 這樣添加樣本這件事就變得很難在實務上進行。
基於上方的種種假設,
我們對 Z 外部資料進行定義:
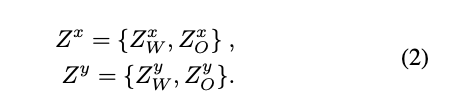
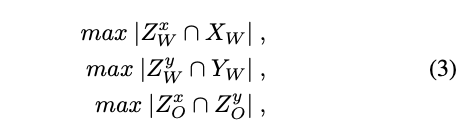
最終所提出的 Domain Bridge 想法可用下方這張圖表示
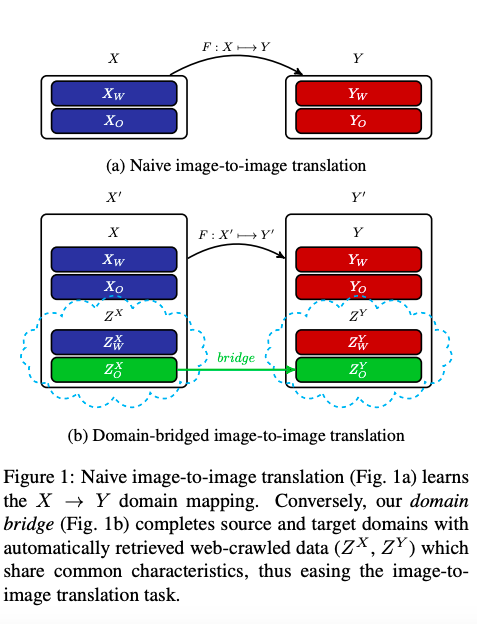
Unsupervised Domain Adaptation(UDA)
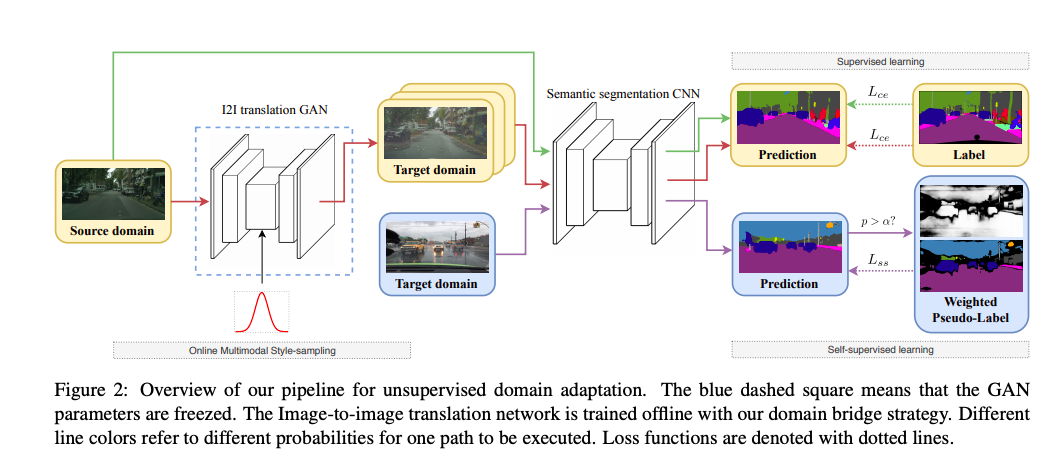
上圖為本文的 UDA 架構,
概念是我們會有兩個資料集
- Source domain (橘黃色) - 有 Label(GT)
- Target domain (淺藍色) - 沒有 Label
我們會希望使用 Source domain + Target domain 所訓練出的模型可以應用在 Target domain 上。
那以往這問題是這兩個資料集間會存在著 Domain Shift 的問題,
單純使用 Source domain 去做 Supervised learning 的模型當應用在 Target domain 時,
其準確度會降低很多。
步驟大概如下
- 輸入 Source domain 的圖片至 Semantic segmentation 的模型去做 Supervised learning
因 Source domain 有 GT label。
- 使用 Source domain 的圖片去做進行圖像畫風轉換成 Target domain 的樣子(以此任務為例,就是將乾淨的圖片轉成下雨的圖片,即為中間 Target domain 的橘色框框處) 之後再進行 Supervised learning(同 1.)
此處的構想是基於圖像轉換過後,圖片的內容不變只有畫風會轉變,所以可以使用 Source domain 有 GT label。(理想上是這樣,但事實上轉換過去還是會有點差),值得注意的是因為我們的圖像生成模型是 Multimodal,因此可以將同一張圖片生成出不同畫風/雨量大小的影像。本文將在訓練過程中生成不同的圖片稱作 Online Multimodal Style-sampling (OMS)
- 使用 Target domain 的圖片至 Semantic segmentation 的模型進行 Self-supervised learning
這邊的想法是 Target domain 的資料集中沒有 GT,因此我們沒辦法進行 Supervised learning,但是我們可以選擇一些信心程度高的 Pixel 來當作 GT 進行訓練,而這部分的難度在於說要如何訂定信心程度 α - (Pixel confidence > α)。 本文將此稱作 Weighted Pseudo-Labels(WPL)
Online Multimodal Style-sampling (OMS)
這部分就是在說訓練過程中,會使用 MUNIT 的 Multimodal 特性,將同一張圖片生成出不同樣子,讓訓練資料的多樣性更多。 
Weighted Pseudo-Labels(WPL)
本文提出的 Self-supervised 策略,
一開始會先初始化設定 α,實驗設為 0.8,
因為一開始模型還不夠穩定,
所以 Threshold 會調高一點,
等之後模型穩定後,會逐漸降低 α。
我們可以看到下圖 Weights 的白色部分。
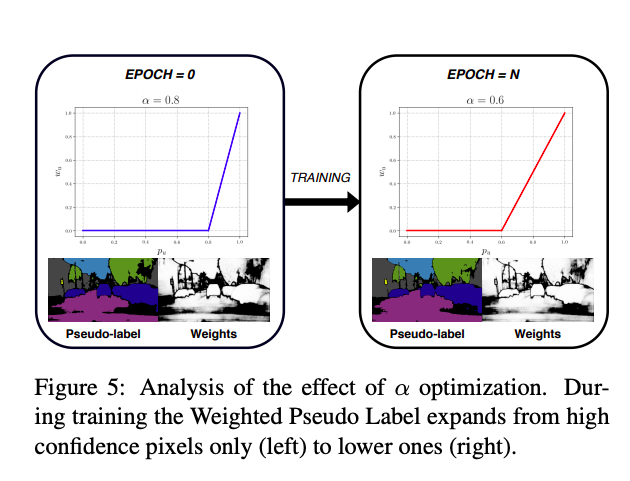
下面就簡單的數學式,
找找看該 Pixel 所預測的哪個類別信心分數最高,
然後比較看看有沒有 >= α
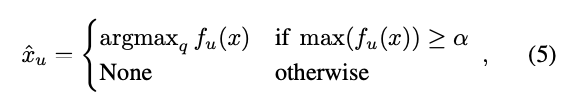
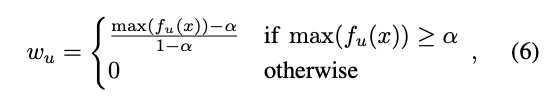
然後結合這個權重 w 當作 Loss,
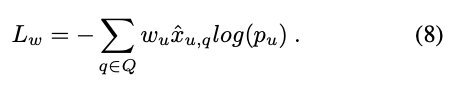
就是 Cross-entropy 再結合 w。
只是說我們要如何讓 α 逐漸的下降呢?
簡單來說我們的 α 其實是一個參數(parameter),
所以可以被模型自動地學習,
只是說我們希望之後的 α 會慢慢的降下去直到平衡。
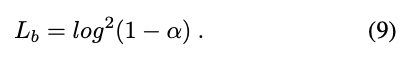
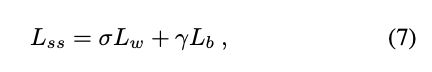
最終使用的時候因 Self-supervised learning 不見得這麼的可靠,
所以 Lss 給定 Ptp (0.75),
就是說學習的時候大概只有 25% 的訓練會使用 Lss 做訓練。
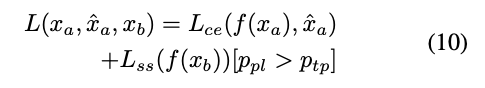
實驗結果
細節不講了有興趣的自己去看!!


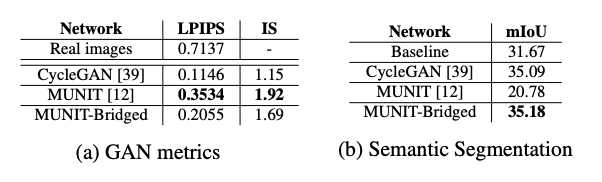
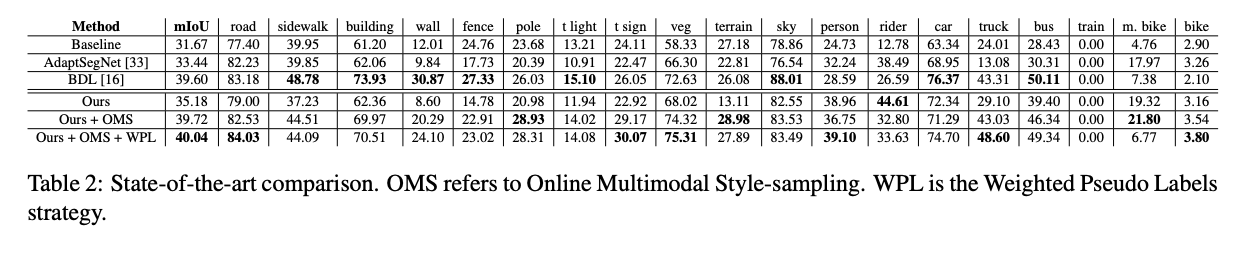
下面這兩個表格的數據其實挺有意思的。
參考資料:
Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation.
ECCV’18 MUNIT-Multimodal Unsupervised Image-to-Image Translation