SSTDA簡介 - Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
Min-Hung Chen, Baopu Li, Yingze Bao, Ghassan AlRegib, Zsolt Kira. Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation. In CVPR’20.
CVPR 2020 paper
Paper link: https://arxiv.org/abs/2003.02824
Github(Pytorch): https://github.com/cmhungsteve/SSTDA

圖片出自: MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation (CVPR 2019)
對於 Action Segmentation 不熟悉的人可以看這個影片 Video - MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation (CVPR 2019)
簡介
此任務是針對影片中的動作進行識別,
而此任務的困難之處在於同一個動作交由不同人做都會有些許的不同,
舉例來說每個人游泳的姿勢都有些許不同,
要如何訓練出一個模型可以適用於所有人的身上是一個難題。
本文提出 Self-Supervised Temporal Domain Adaptation(SSTDA) 的模型,
概念是使用 Unlabel 的資料集來使模型能夠有更好的泛用性(註1),
遇到沒看過的影片或是動作有不同時一樣能有好的泛用性,
本文所提出之方法簡單來說是透過將現有資料集切分成兩部份,
再使用 Domain Adaptation(DA)的方式進行自我學習(註2)。
而在影片任務中往往要考量時空間(Spatial temporal) 的關係,
簡單來說不只是需要看目前這個 Frame 的圖片,還要考量前面幾個 Frames 所得出的結果,
因此此模型會針對單張圖片(Frame-level)以及影片-多張圖片(Video-level)進行 DA。
Note:
註1. 使用 Unlabel 的資料不外乎的考量就是標註的成本, 因影片動作識別的任務需將影片中的每一張畫面都標記動作,這是一個相對費時費力的任務,如果能使用 Unlabel 的方式進行增強,那這方法是相對實用的。
註2. 雖說是 DA 的概念,但此任務是將一個資料集切成 Label 以及 Unlabel 兩個部分,因此這兩部分的動作種類是相同的, Domain shift 的問題也相對不大,與前幾年 Domain adaptation 的任務設定不太相同(e.g. CG to Real-world or 兩個不同畫風的資料集)。
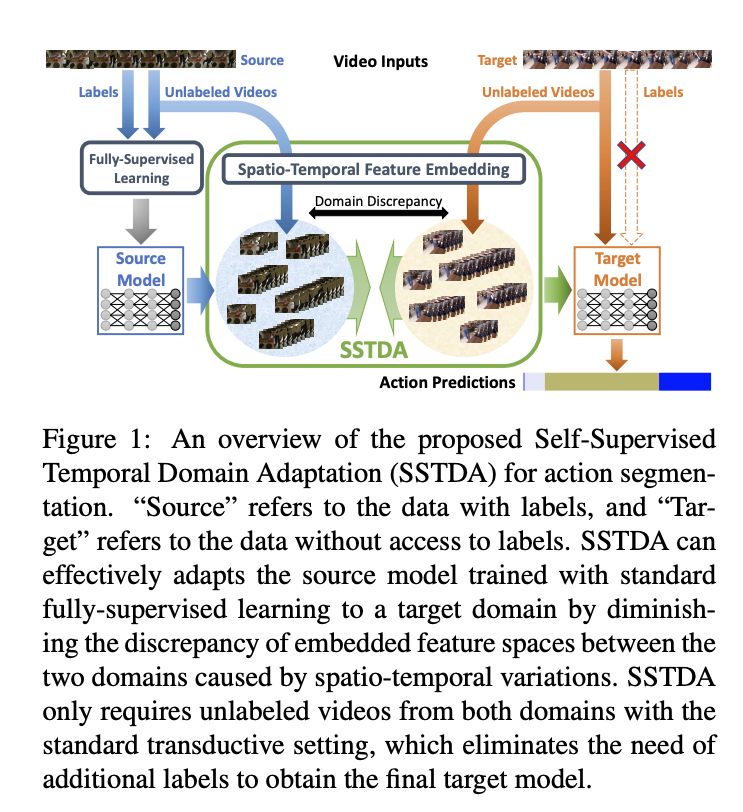
方法
整體架構是採用 MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation 為基底結合本文所提出的 Self-supervised 方法。
本文提出兩個 Self-supervised 的 Domain adaptation 方法,
- Local SSTDA - Lld
- Global SSTDA - Lgd
首先將資料及分成有標籤(Label)以及沒標籤(Unlabel)的資料,
在 DA(Domain Adaptation)的領域中,我們習慣將有標籤的稱之為 Source Domain,沒標籤的稱之為 Target Domain。
DA 的概念是希望學會的 Feature 不會因為不同環境(Domain)而影響到預測出的特徵,
換言之,希望學習出一個泛用的模型其輸出的特徵不會受到環境影響(Domain-invariant)。
當這種情況時分類器應該要無法分辨出這特徵是從 Source or Target domain 而來的,因此輸出的機率為 0.5,
因為分類器如果能準確分類出 Source or Target domain 的話那代表這特徵應用到另一個 Domain 的時候可能不具備通用性。
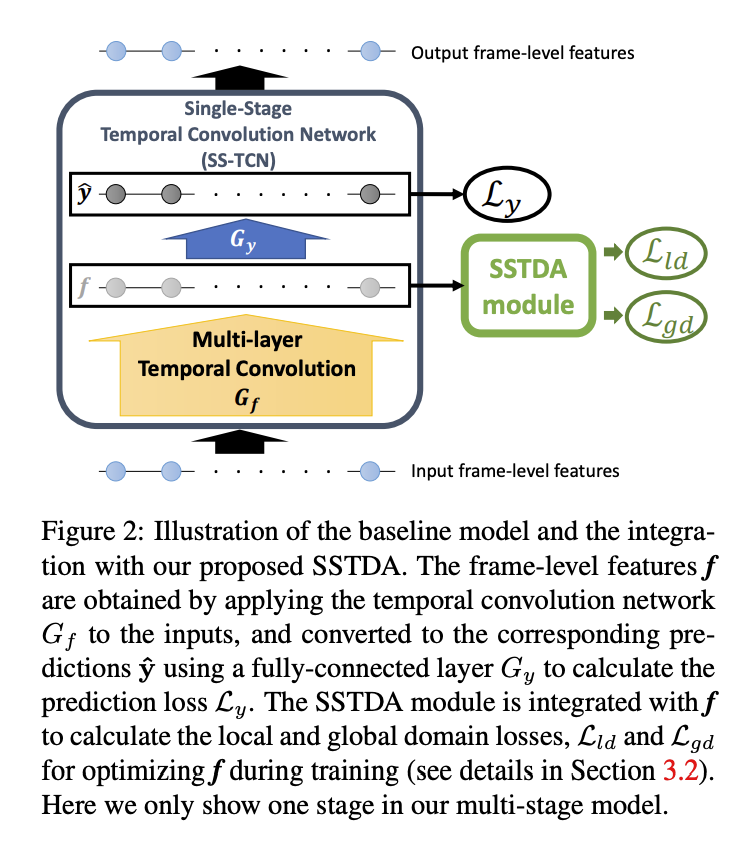
Local SSTDA
透過 SSTDA module 將單張圖片(Frame-level)預測為 Source or Target domain,再藉由 GRL - Gradient reversal layer 訓練模型學出 Domain-invariant features。
對這部分不太清楚怎麼做的可以看這邊論文 Unsupervised Domain Adaptation by Backpropagation
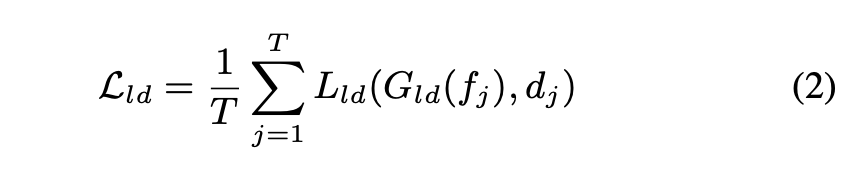
Global SSTDA
概念與 Local SSTDA 相似,只是這部分考量到影片中的時間關係,換句話說是不只考量目前圖片而是要考量整個影片,因為影片會有連貫性。
而影片部分最讓人在意的是如何處理不固定的影片長度做為輸入,
這邊採用的是 Domain Attentive Temporal Pooling(DATP),
透過給予不同 Frame 不同的權重,藉此將影片中 Frames 的特徵整合,
透過下面方式就可以處理不固定的影片長度,將所有 Features 搭配權重加起來
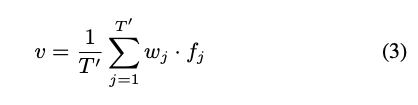
而權重的獲得方式是基於 Local SSTDA 所預測出的比重。
簡單來說是讓模型可以更專注將這些可被清楚分類的 Features 朝向 Domain-invariant features,因此才會給定不同的權重。
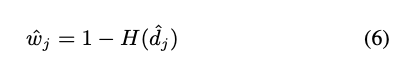
而這邊還提出使用 Residual 的方式來穩定模型訓練。
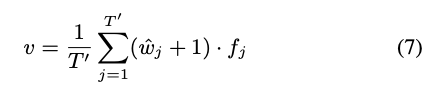
訓練方式和 Local 的 SSTDA 一樣 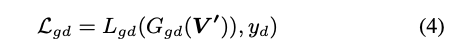
模型架構
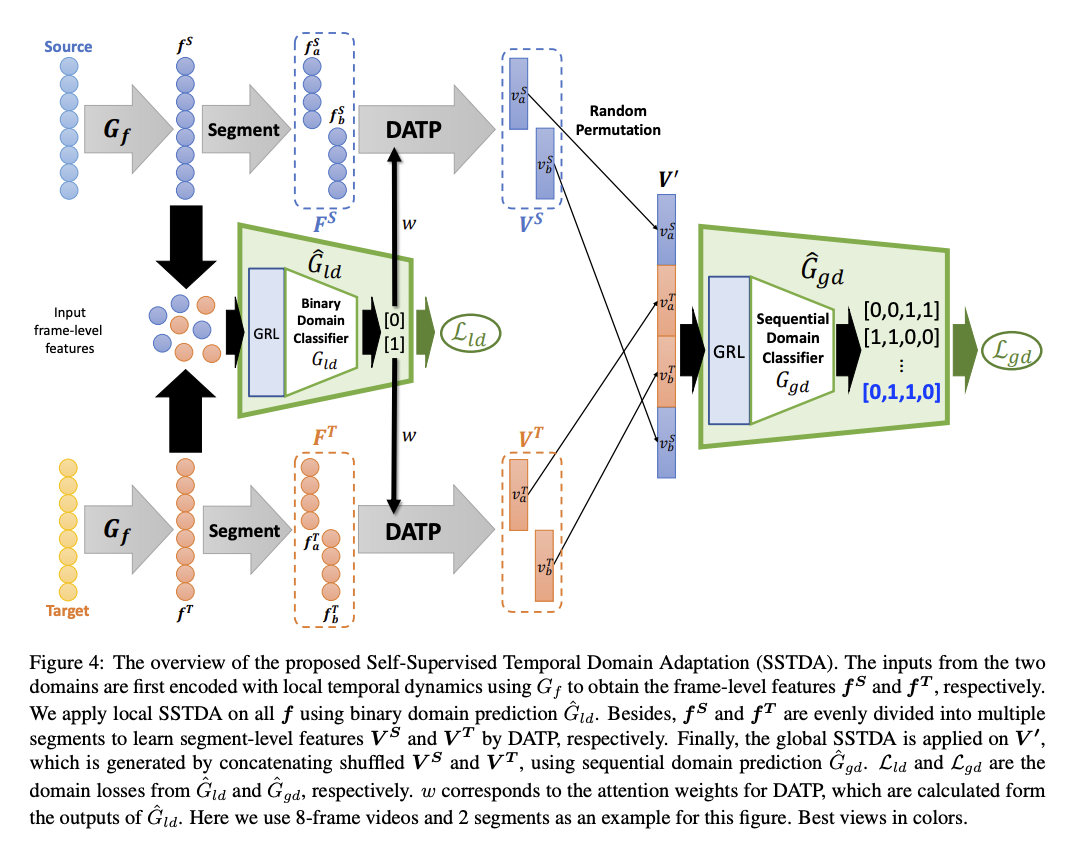
Note:其實這裡的 Binary domain classifier 是使用 2 個 output,分別代表著 Source 以及 Target Domain,並非只有 1 個輸出,可以看上方架構圖中 Gld 的輸出分別為 {[0], [1]},所以實際上程式碼會比較複雜一點。
Trick: 將最後得出的不同片段的 Feature 進行重組,可以看到圖片中右半部 V’ 的部分。
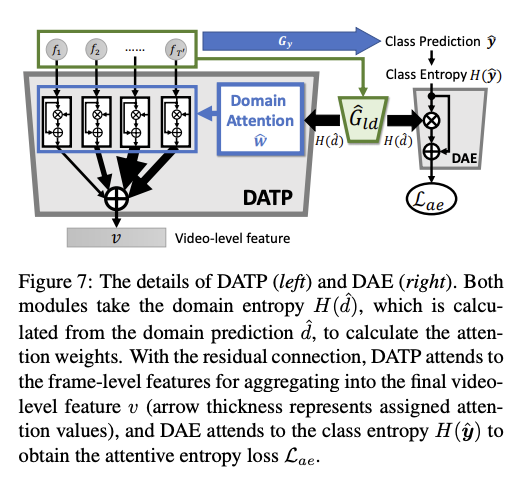
Domain Attentive Entropy(DAE)
這部分是在附錄中的 Trick,
簡單提一下,目的是希望最小化類別的 Entropy,基於該模型已經可適應好 Source 以及 Target domain 的情況下。
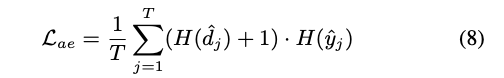
概念:當 Frame 的 Feature 讓模型無法準確分類出是 Source / Target 時,此時的 H(d) 是會最高的, 而此時我們希望類別的 H(y) 要低的,這樣子該 Loss 才會變低。
H(y) 低 => 類別分類的機率只有一個高其他都低,反之當所有分類的機率都很平均時,此時 H(y) 會變高,導致此 Loss 變高。
整體 Loss 如下
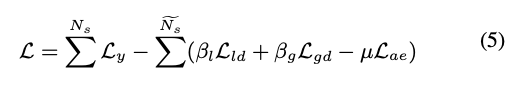 Note: Ly 是使用 Label 的資料進行 Supervised learning。
Note: Ly 是使用 Label 的資料進行 Supervised learning。
最終架構
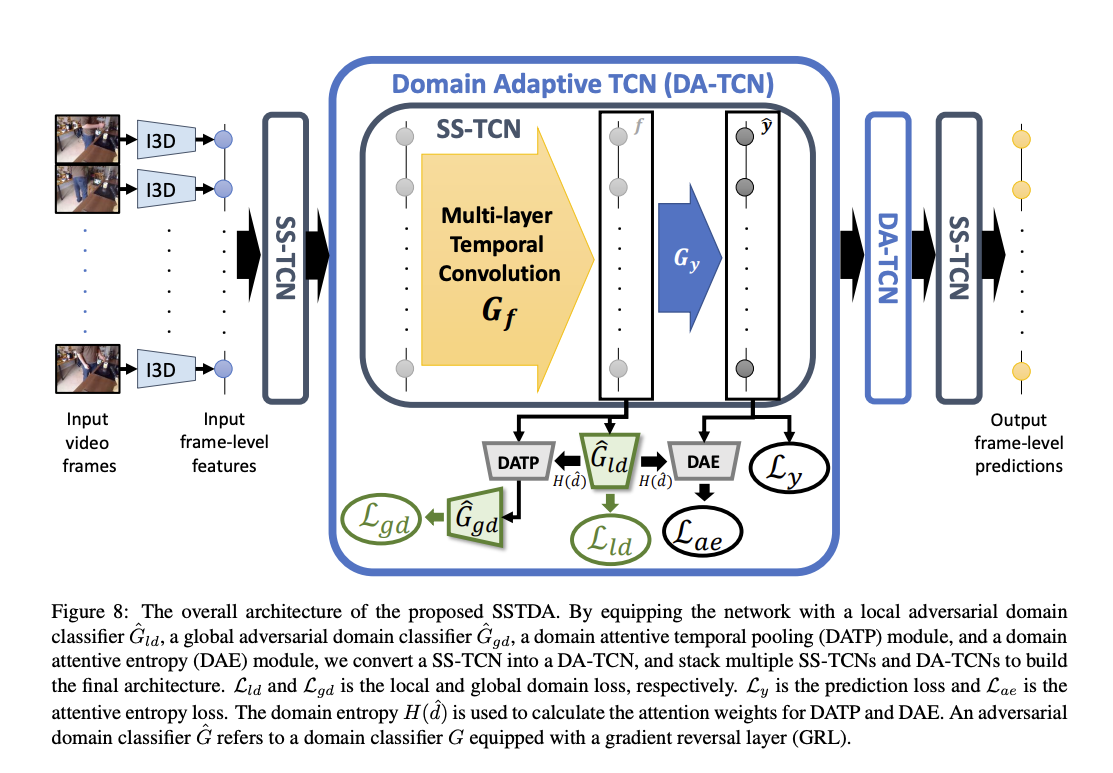
實驗發現在第2, 3層採用 DA-TCN 的架構是最好的,若在第一層就採用會因為學到的特徵還是屬於 Low-level 特徵的並不具辨別性,而在最後一層也不見得好。
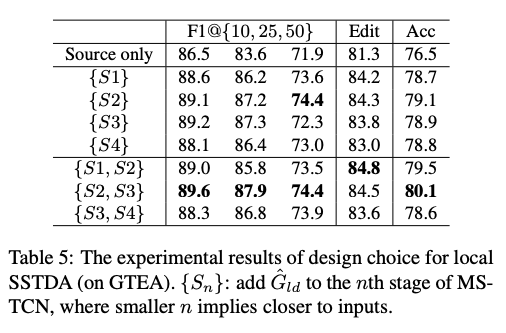
因此最終的 Loss function 會變成下面這樣 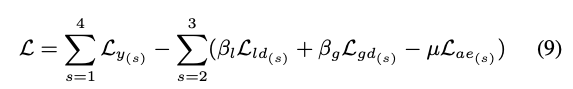
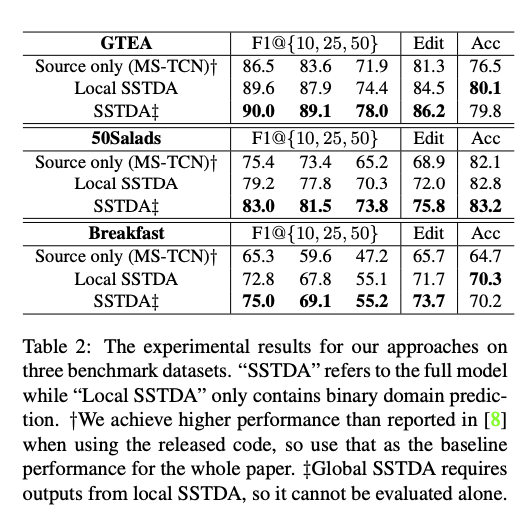
實驗部分
下方各模型的顏色代表與 GT 不同的部分。

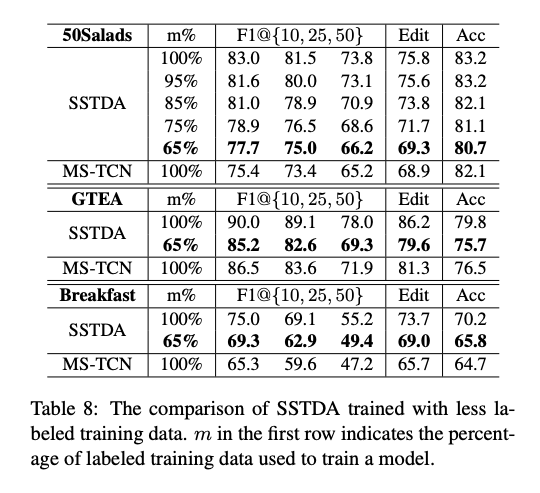
透過此模型只要 65 % 的訓練資料就可達到與 MS-TCN 的模型差不多的效能。
參考資料:
Action Segmentation with Joint Self-Supervised Temporal Domain Adaptation
MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation
Video - MS-TCN: Multi-Stage Temporal Convolutional Network for Action Segmentation (CVPR 2019)