CUT簡介 - Contrastive Learning for Unpaired Image-to-Image Translation
Taesung Park, Alexei A. Efros, Richard Zhang, Jun-Yan Zhu. Contrastive Learning for Unpaired Image-to-Image Translation. In ECCV’20.
ECCV 2020 paper
Paper link: https://arxiv.org/abs/2007.15651
Github(Pytorch): https://github.com/taesungp/contrastive-unpaired-translation
Video link: https://www.youtube.com/watch?v=jSGOzjmN8q0
有時間的人非常推薦觀看,下文大量使用影片所使用之投影片。
簡介
本文對於非監督式圖像轉換任務(Unsupervised image-to-image translation)提出新的框架,
該框架擺脫以往 Cycle-GAN 需要 2 組 GAN 並使用 Cycle-consistency loss 的架構,
改為利用對比學習(Contrastive Learning)來鼓勵輸出的圖片相似輸入圖片,
因此該模型只需要一組 GAN 即可進行圖像轉換,
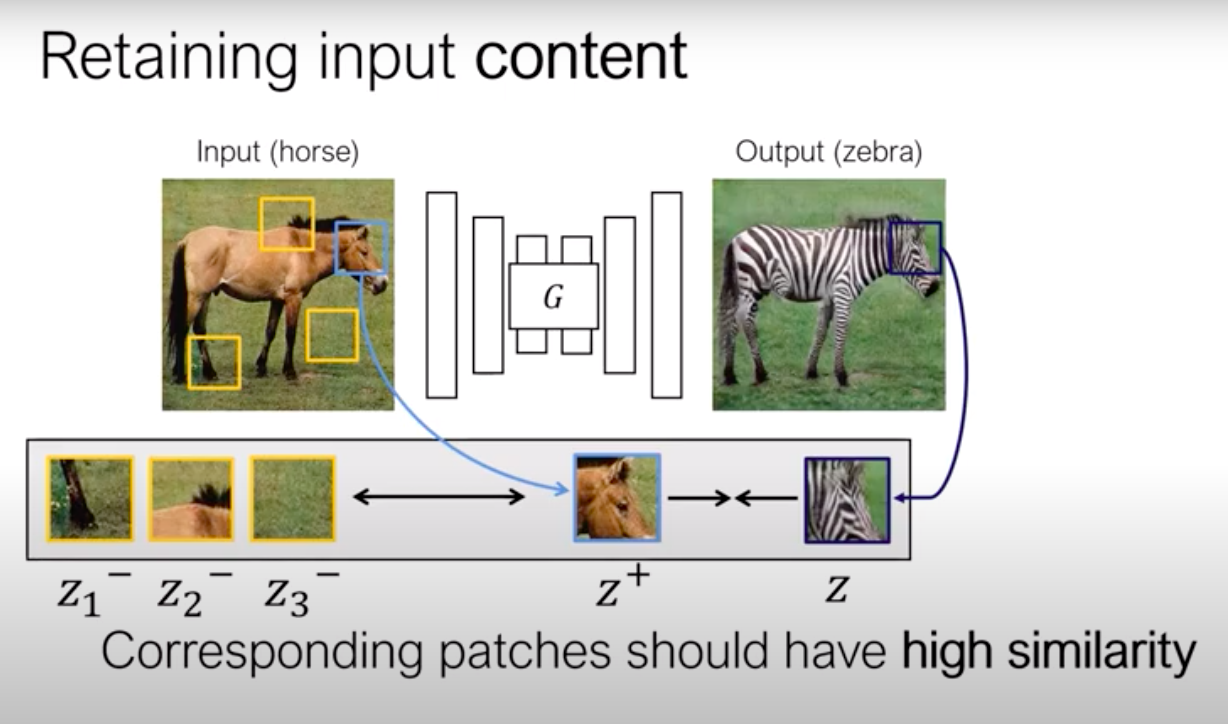
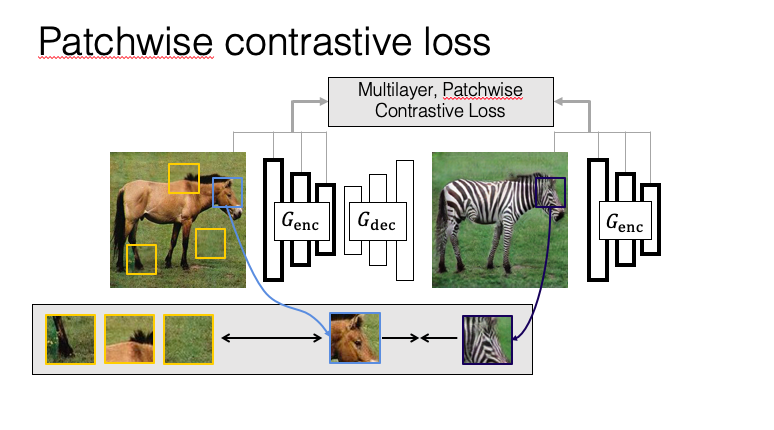
以下圖為例,透過對比學習讓右邊斑馬的頭部區塊要相似左邊馬的頭部,
並且利用斑馬的其他部位或是背景(e.g., 腳、草地等)作為負樣本(Negative),
透過這概念將整張圖切分為圖像區塊(Patch)進行對比學習。

概念
以馬變成斑馬的圖像轉換任務為例,
模型會希望將馬的部分可以轉換成斑馬,
此部分我們稱作外觀(Apperance),
而背景或是其他部分保持不變,此處稱作結構(Content)。
以往的做法是透過 GAN 的對抗式學習來讓外觀部分學習如何變成斑馬,
並利用 Cycle-consistency loss 來學習兩者的關聯性,
然而這項條件有時候其實是太過嚴苛,
以下圖斑馬轉換成馬的任務為例,
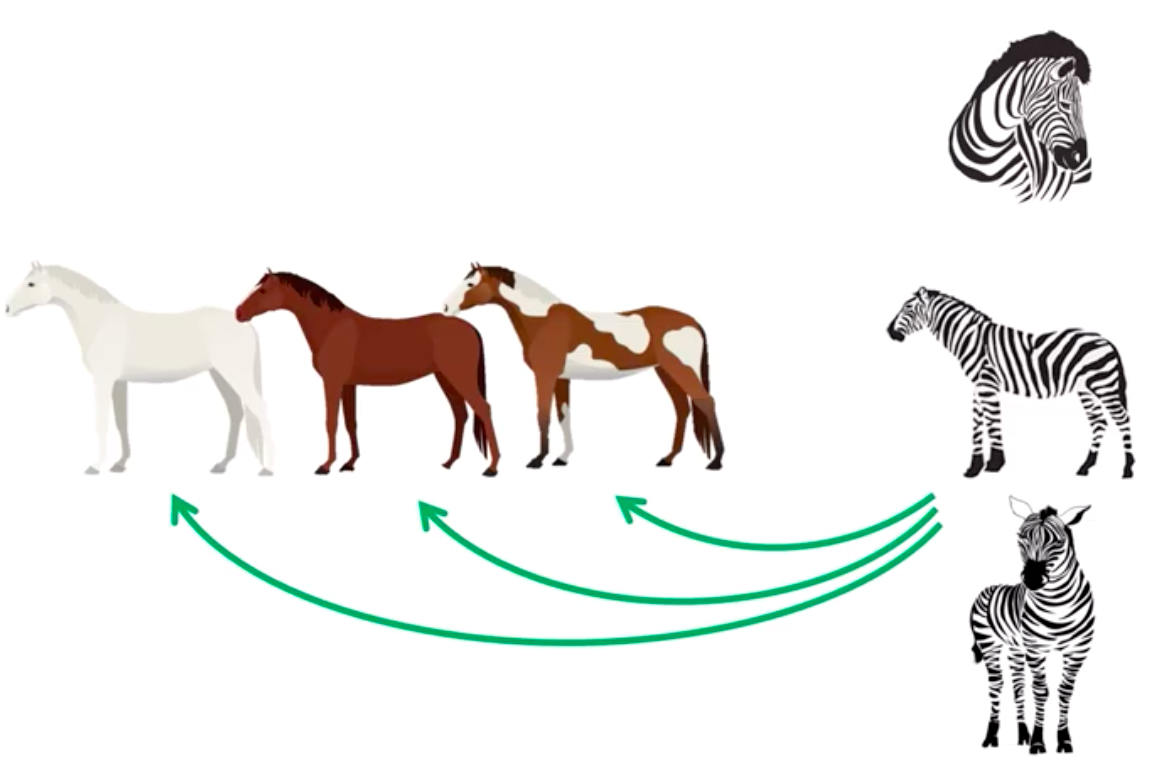
假設一開始是棕馬轉換成斑馬,之後再從斑馬轉換成白馬,
但僅僅是顏色變換就會使 Cycle-consistency loss 認為這轉換的不好。
下圖為 Cycle-consistency loss 的示意圖。
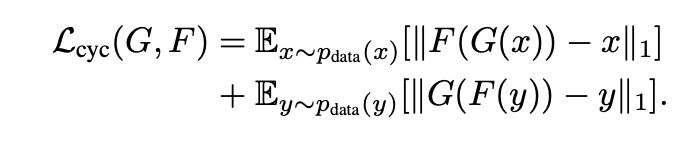
因此本論文提出一種替代方法,
透過學習 Mutual information 來學習圖片中的結構,
此概念是來自該篇論文 INFONCE Loss - Representation Learning with Contrastive Predictive Coding
在非監督式的學習中,希望能讓模型學會高階的特徵,
透過 Mutual Information(相互資訊) 的概念去學習一個 Latent vector - c。
未來可透過該 Latent vector 只要在結合幾層 Linear classification 就可以有不錯的分類效果。
最終達成不需 Cycle-consistency loss 就可以有不錯的圖像轉換效果。
模型架構
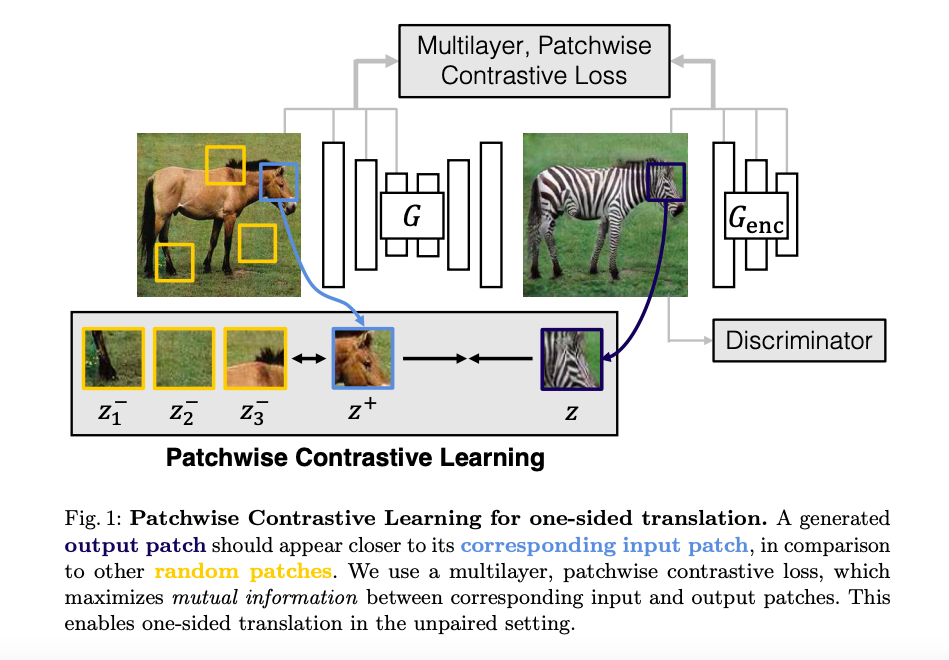
Step1. Adversarial learning
首先將一張圖片經過 Generator 生成出圖片接著進行對抗式學習,
讓 Generator 經由 Adversarial loss 來學習如何輸出一張像目標種類的圖片。
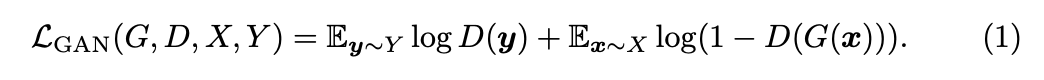
接著我們補充一些生成器的細節,
雖然架構圖上面寫 G(Generator),
但其實 G 是由 Encoder 和 Decoder 組成。
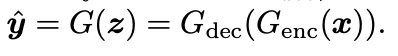
Step2. Contrastive learning
接著會進行對比訓練(Contrastive learning),
簡單來說我們要希望模型可以有效的學會某個特徵時(稱做 Query),
我們會利用正樣本(Positive)以及負樣本(Negative)來學習,
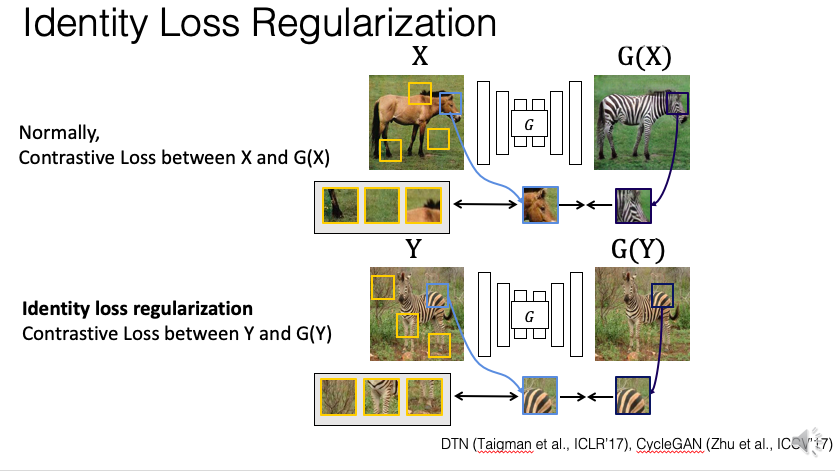
而在圖像轉換的任務中可以透過提取相同圖像位置的區塊作為正樣本,
而其他部分就是負樣本。
將輸入圖像以及轉換後的圖像相同區塊(下圖為馬的頭)的部分我們希望越像越好,
而馬的頭與其他部分(馬的背、馬的腳、背景)與馬的頭不相關的部分越不像越好,
因此在做的事情等同於利用 Cross-entropy 在訓練分類器。

寫成數學式就會變成這樣, v+(Postive)、v-(Negative)
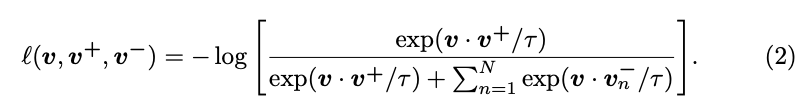
值得一提的是以往是透過整張圖片來進行對比學習,
MoCo: He et al., CVPR20; SimCLR: Chen et al., ICML20
而本論文是基於圖像區塊(Patch)來實作的。
補充架構的細節:整體架構是 Generator(Encoder + Decoder) + Discriminator + MLP Network(H)
以往 GAN 架構只要 Generator + Discriminator,
而本文增加對比訓練,
因此還會透過 Generator 中的 Encoder 與 MLP 進行對比學習。
Multilayer, patchwise constractive learning,
簡單來說是依據不同大小的圖像區塊進行學習,
Encoder 中不同的 Layer 所輸出的特徵大小不同,
而利用不同尺度的特徵進行對比學習可以讓模型學得更好。
而接著也對資料集內(External)的所有圖片進行對比學習,
然而成效卻沒有 Patch 的方式好。

而作者也提出了該原因可能是因為利用其他圖片的 Patch 會不小心取樣到 Positive 的部分卻作為 Negative 做學習,
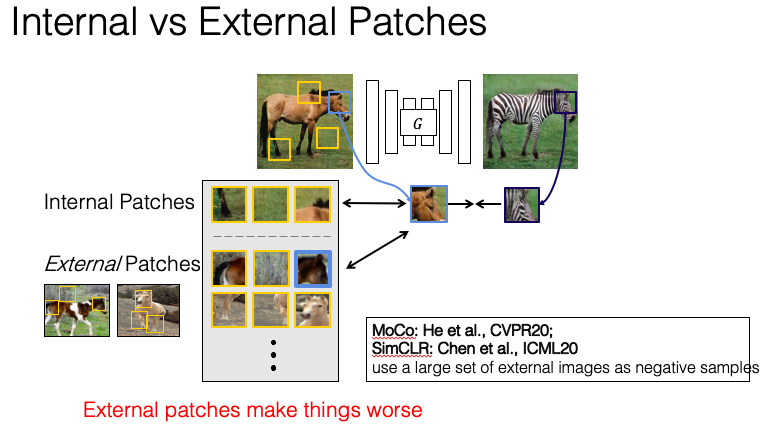
如上圖,當我們目前所 Query 的是馬的頭部,
但當取樣整個資料集時,
我們不知道該圖片哪個部分是馬的頭部,
所以可能會取錯圖片區塊,造成 False negative。
最終的訓練公式如下:
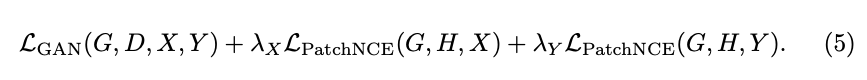
上方的 𝜆y 指的是 Identity loss。
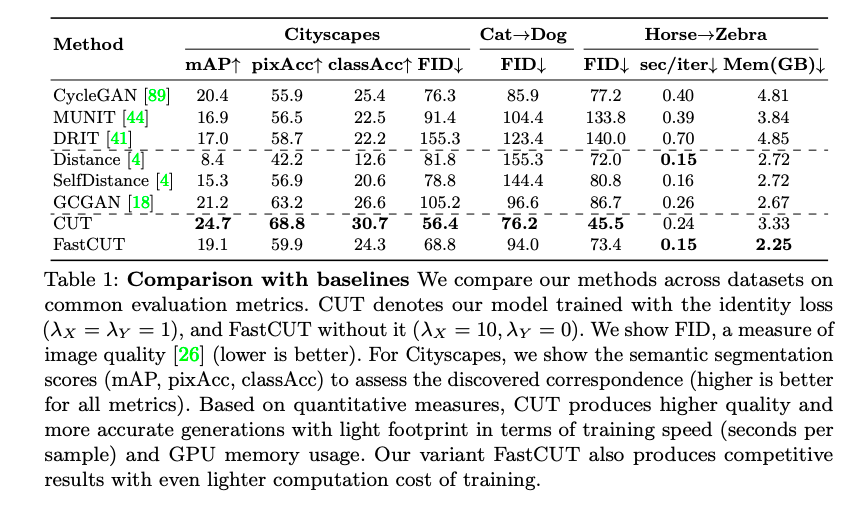
成果
而本文提出兩種設定
- CUT(採用 Identity loss): 𝜆x = 1, 𝜆y = 1
- FastCUT(不採用 Identity loss): 𝜆x = 10, 𝜆y = 0
Last layer only 指的是沒有使用 Multilayer 的方式做對比學習。

透過視覺化解釋 Encoder 有辦法呈現整張圖與該點相關性。

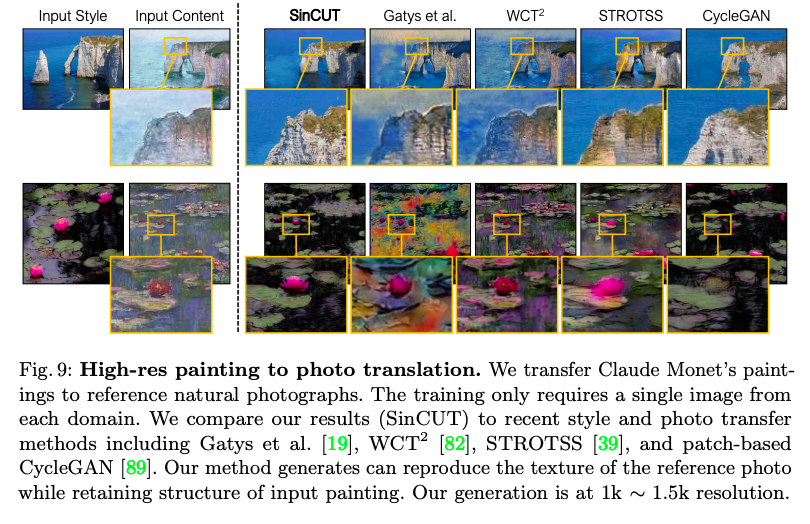
透過將高解析度的影像拆解成小區塊(128 x 128)訓練,
此處有一些細節如送進 Discriminator 會再切分成 64 x 64 的圖像大小等等的,稱之為 SinCUT,
有興趣的去看實驗部分,下方為高解析度畫風轉換。
在 GTA5 以及 Cityscapes 的畫風轉換。

參考資料:
Contrastive Learning for Unpaired Image-to-Image Translation
Youtube CUT: Contrastive Learning for Unpaired Image-to-Image Translation
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks