YolactEdge簡介 - Real-time Instance Segmentation on the Edge
Haotian Liu, Rafael A. Rivera Soto, Fanyi Xiao, Yong Jae Lee. YolactEdge: Real-time Instance Segmentation on the Edge. In ArXiv preprint(IEEE under review).
Paper link: https://arxiv.org/abs/2012.12259
Github(Pytorch): https://github.com/haotian-liu/yolact_edge
Slides link(YolactEdge Review [cdm] by Dongmin Choi): https://www.slideshare.net/DongminChoi6/yolactedge-review-cdm
有時間的人非常推薦觀看。

簡介
本文基於 YOLACT: Real-time Instance Segmentation 進行速度上的優化,
使其可運行於邊緣運算設備的實例語意分割模型 (Instance Semantic Segmentation),
以往所稱可即時運行的實例語意分割模型通常是指運行在 RTX 2080 左右等級的顯示卡上,
而本文提出可在 AGX Xavier 可達 30.8 FPS、RTX 2080 Ti 上可達 172.7 FPS 的方法,
其可支援的圖片大小為: 550x550。
下方圖表取自 Github: YolactEdge
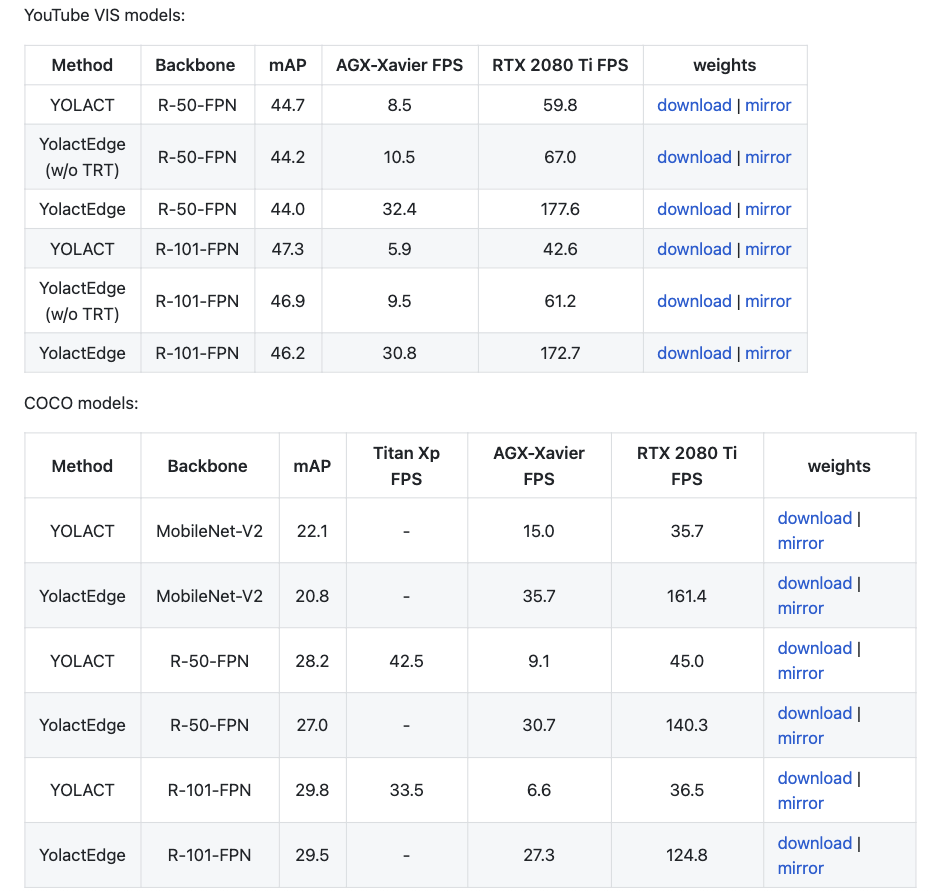
該框架特別之處為:即便要部署在邊緣運算設備上,為了準確度仍採取了 ResNet-101 FPN 的模型,
並沒有單純為了速度而採用 MobileNetv2 來加速。
即便如此卻還能達到 Real-time 的 30 fps。
整體而言進行了下方幾點的優化
利用 TensorRT 進行推論(Inference)加速,運算精度改至 FP16 or INT8。
捨棄以往 YOLACT 利用單張影片進行辨識,改為影片的概念進行加速,利用影片有高度連貫性的特性,節省計算重複特徵,以達到加速,因此原文寫:『 YolactEdge - the first video-dedicated real-time instance segmentation method. 』
Yolact 快速複習
本文基於 YOLACT: Real-time Instance Segmentation 即時的實例語意分割模型,
雖然早幾年寫過 YOLACT簡介 — Real-time Instance Segmentation,
有興趣的可以去看看,不過現在看來當初寫的簡介還有很多地方可以加強呢。
因此我這邊會簡單的介紹一下 YOLACT,
YOLACT 是早年第一個即時的實例語意分割模型,
不過他是運行在 Nvidia Titan Xp 才能達到 33.5 fps。
模型的整體概念是將 Two-stage 的 Mask R-CNN 的進行改善,
下圖為轉載自 Ivan 物件偵測 S9: Mask R-CNN 簡介
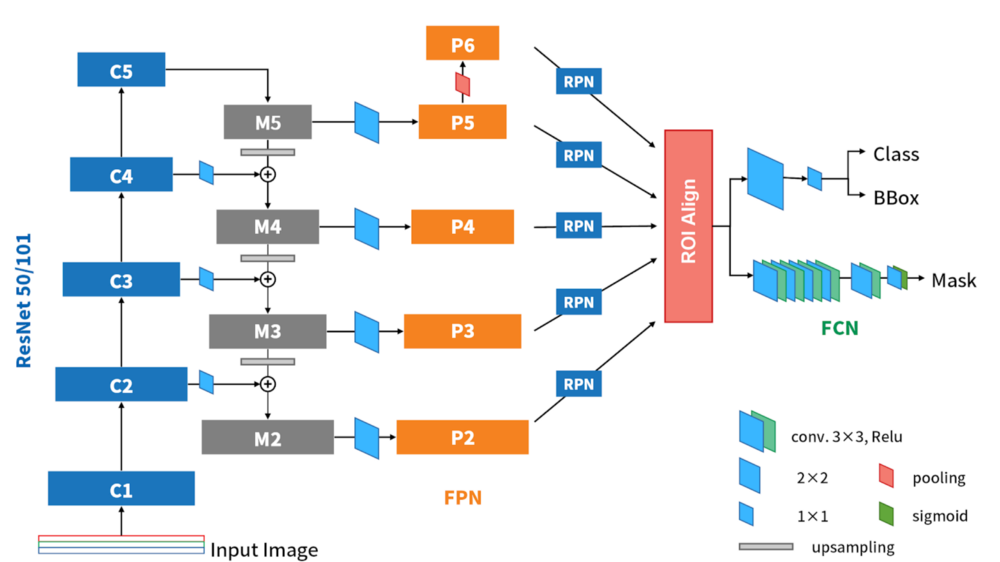
簡單來說 Mask RCNN 的 Two-stage 架構為
- Backbone 第一階段萃取特徵
- Feature Pyramid Network(FPN) 第二階段萃取特徵
- Region Proposal Network(RPN) 提取出物件有可能的位置 ROIs(Region of Interests) 尺寸較小
- ROI Align 將 ROIs 的尺寸還原回原圖大小,由於是語意分割像素級別(Pixel level)的任務,因此會盡可能的還原回原本圖片的尺寸,藉此增加圖像分割的精準度。
- Prediction 分類該像素點的類別以及輸出各個物件的語意分割。
下圖為 Mask R-CNN vs YOLACT vs YolactEDGE 
YOLACT 指出 ROI Align 的步驟太過於耗費時間,
因此提出輕量化的方式,透過線性組合/矩陣相乘的方式來達到更快的實例語意分割模型。
主要概念是使用多個遮罩(Mask,此文稱作 Prototype),
搭配多個係數(Coefficients)來進行線性組合出實例語意分割輸出,
這也是為什麼此模型稱作 YOLACT:You Only Look At CoefficienTs,
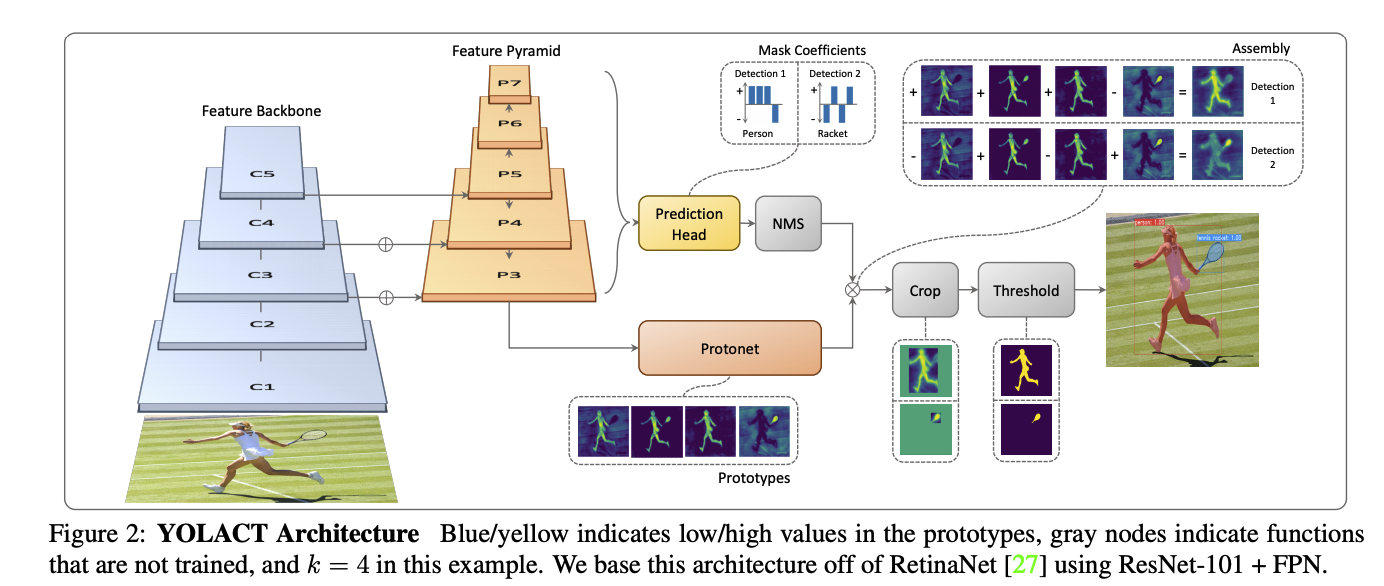
其特點為 Protonet(Mask) 是直接由 Feature Pyramid Network 的 P3 層所輸出,
可發現其尺寸是相對大的,因此不需要像 Mask R-CNN 為了還原高解析度而再進行一次 ROI Align。
而後續會針對 YOLACT 的四個架構進行探討,因此要先記好各個部分在架構圖的哪邊。
- Feature Backbone
- Feature Pyramid
- Protonet
- Prediction Head
複習時間
剛剛介紹太多 Yolact ,
可能大家已經忘記這篇是在介紹 YolactEdge,
接下來我們將會探討 YolactEdge 的兩個主要貢獻:
- YolactEdge 利用 TensorRT 藉由降低運算精準度來加速預測時間。
- Yolact 是基於單張圖片的實例語意分割模型,而 YolactEdge 改為利用影片關聯性的方式,節省某些特徵的計算。
YolactEdge 概念
TensorRT
簡單來說,TensorRT 是 Nvidia 所提出的一個專為優化深度學習推論模式(Inference)的套件,
使其在運算時可以有著較低的延遲,
這篇論文最主要用到的是 Mixed Precision 的部分,
TensorRT 提供精度 INT8 和 FP16 優化。
如果有興趣可以去看這篇 TensorRT 介紹與安裝教學 by 李謦伊。
因此 YolactEdge 針對 Yolact 的四個不同架構進行實驗,
評估各架構用 FP16 或是 INT8 是否可以兼顧準確度以及提升運行速度。
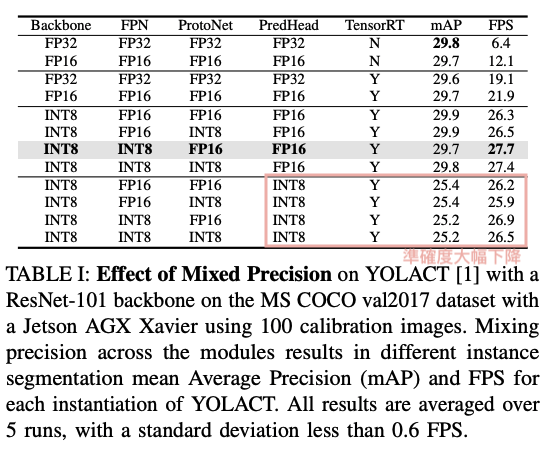
最終選定
- Feature Backbone(INT8)
- Feature Pyramid(INT8)
- Protonet(FP16)
- Prediction Head(FP16)
實驗中發現只要在 Prediction Head 採用 INT8 的準確度都會下降。
而這邊有一個小細節,就是使用 INT8 的精度進行推論的話需要再進行校正的訓練,
簡單來說就是針對值域進行校正,
希望 INT8 和 FP32 的數值分佈要是相近的,
因此會透過 KL-divergence 去優化神經元的分佈要相似,
這邊可以根據 Nvidia 的文件去了解細節。
Fast INT8 Inference for Autonomous Vehicles with TensorRT 3
下圖取自:Szymon Migacz, “8-bit Inference with TensorRT,” NVIDIA 2017.
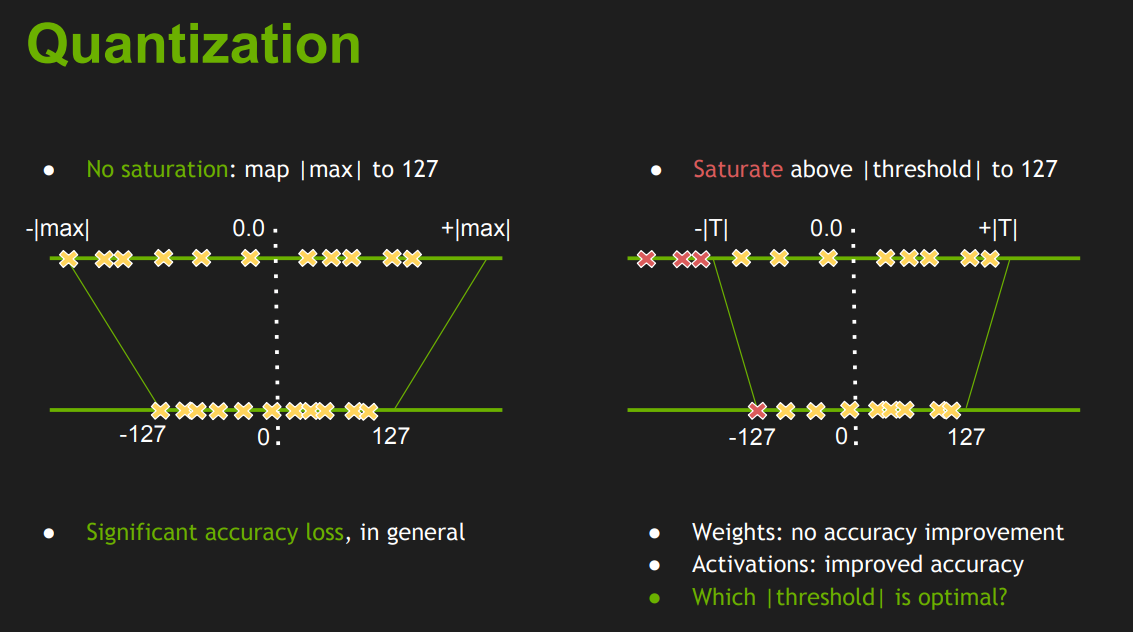
題外話:
我個人還挺喜歡 Fastai 教的 Deep Learning 的課程,在 Fastai Lesson 6 - Deep Learning for Coders (2020) 中也有提到將 FP32 降低到 FP16 使得訓練速度能更快,多半準確度甚至更好,挺有意思的。
影片模式加速模型
相較於 Yolact 是基於單張圖片的實例語意分割模型,
YolactEdge 改為基於影片的實例語意分割模型,
其可有效的利用影片中每個畫面間的關聯性,
藉此可節省某些特徵的計算,優化整體速度。
因此我們會把參考影像(前一幀 Previous keyframe)稱作關鍵幀 Keyframes - Ik,
而當前在處理的影像(Current non-key frame)稱作一般幀 Non-keyframes - In。
大致的概念是我們可以提取前一幀的特徵來節省當前影像的特徵計算。
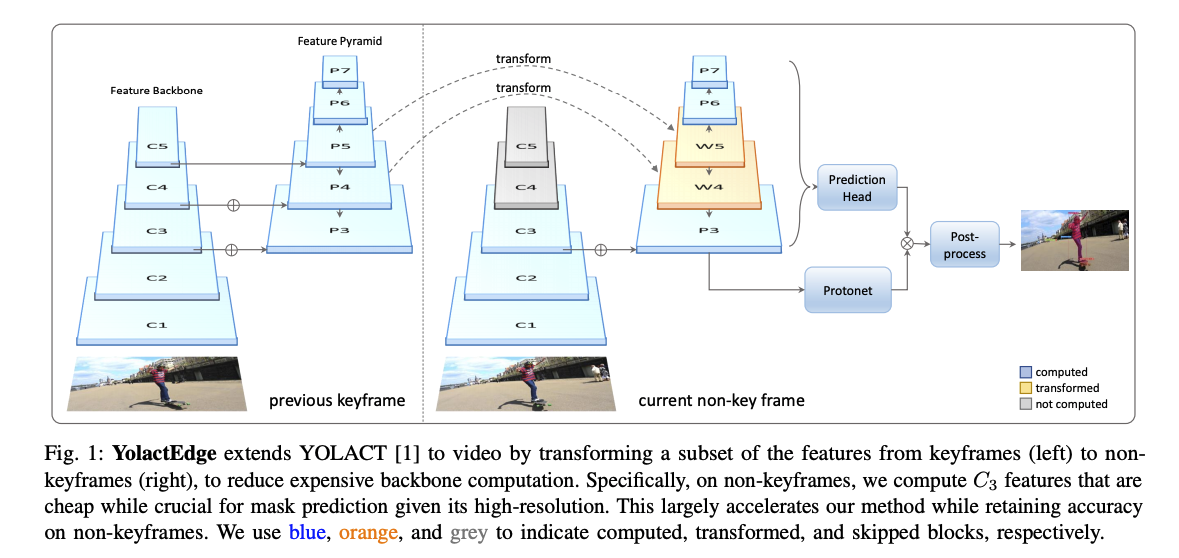
簡單來說整體是透過省略計算 Backbone 的 C4、C5 層(灰色部分)來達到加速,
這是因為實驗中發現 Yolact 的運算主要集中在 Backbone,
那再深入去探討,發現在 C4、C5 層中計算耗費最多,
佔據 Backbone 的 66% 計算。
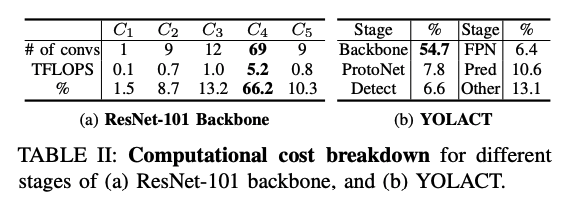
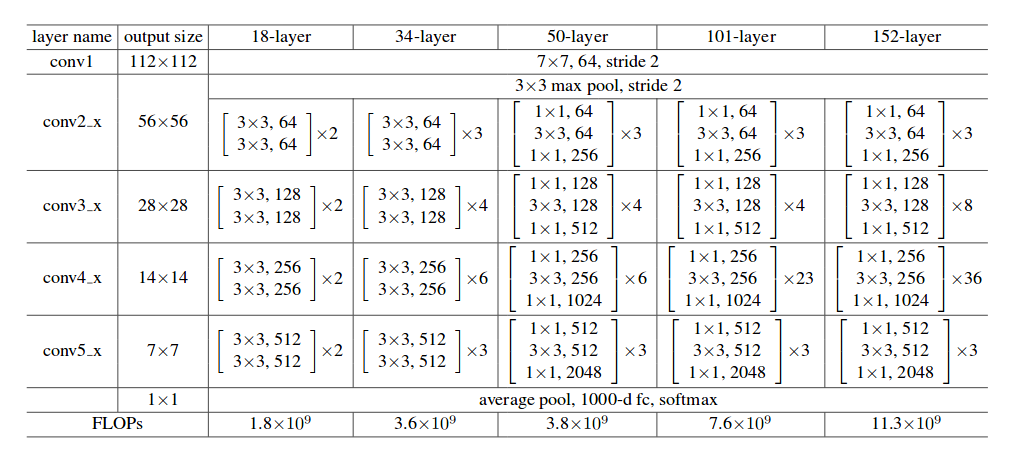
這邊可以參考 Resnet 的架構圖。
因此提出透過前一幀的 P4、P5 層特徵直接轉換(Transform)至當前幀的 W4、W5 就可以省去當前幀 C4、C5 層(灰色部分)的運算。
而實驗中也有探討不同層的轉換,這邊不細講。

Transform - Motion Estimation
以往對於 Frame-by-Frame 的處理,
最常見的是採用光流法來理解兩張圖片之間的變化,
而以往這種方法都是直接輸入 RGB 的圖像接著搭配一堆 CNN 運算,
但這往往需要很大的計算。
下圖取自 FlowNet: Learning Optical Flow with Convolutional Networks
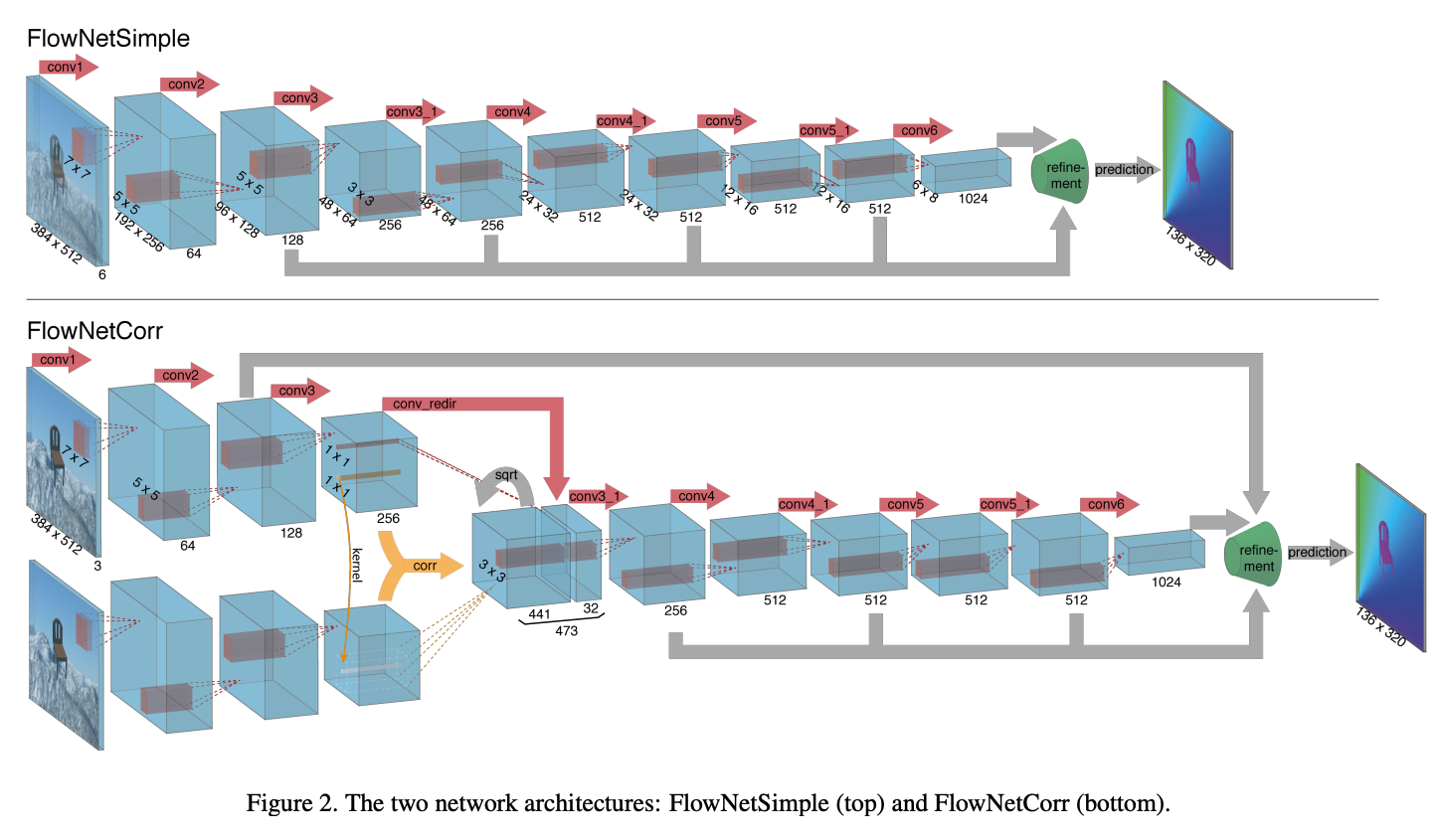
而本文因為注重速度,
如果直接拿現有的模型結合,
會導致運算時間增加,
本文改良成可重複利用原有特徵的架構,
透過原有的 Backbone 萃取特徵後再進行預測光流法。
Note:上個部份提到 C4、C5 層中計算耗費最多,
因此這部分的 Backbone 也是只會運算到 C3 後就輸出。
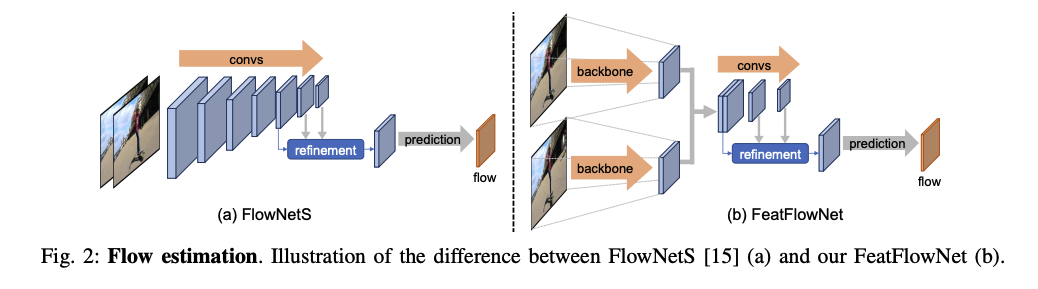
透過光流法的預測可以直接對上一幀的特徵進行轉換(Transform),
而這整串流程就稱為部分特徵轉換(Partial feature transforms),
透過這改善可有效地利用影片中的關聯特性,
加速處理影片的即時實例語意分割。
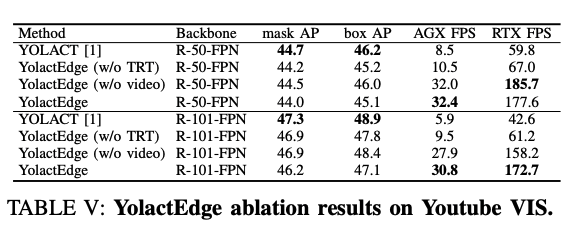
成果

- TRT: TensorRT
- Video: Partial feature transforms
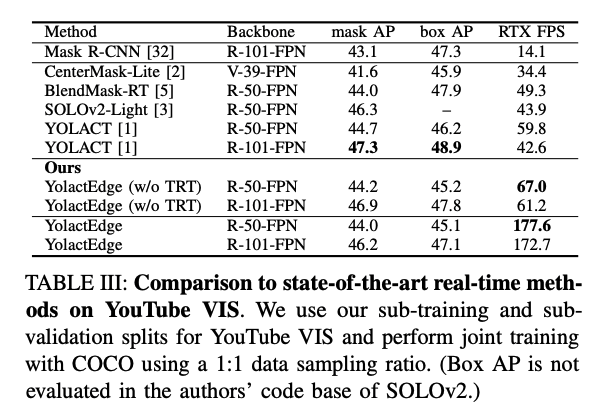
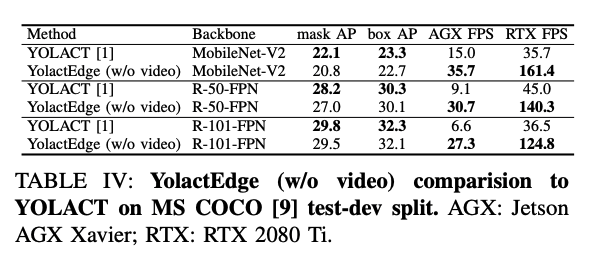
參考資料:
YOLACT: Real-time Instance Segmentation
YOLACT簡介 — Real-time Instance Segmentation
YolactEdge: Real-time Instance Segmentation on the Edge
Szymon Migacz, “8-bit Inference with TensorRT,” NVIDIA 2017.