Pixel2style2pixel(psp)簡介 - Encoding in Style a StyleGAN Encoder for Image-to-Image Translation
Elad Richardson, Yuval Alaluf, Or Patashnik, Yotam Nitzan, Yaniv Azar, Stav Shapiro, Daniel Cohen-Or. “Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation”. In CVPR 2021.
In CVPR 2021.
Paper link: https://arxiv.org/abs/2008.00951
Github(Pytorch): https://github.com/eladrich/pixel2style2pixel
Colab(可直接跑程式碼看結果):https://colab.research.google.com/github/eladrich/pixel2style2pixel/blob/master/notebooks/inference_playground.ipynb
簡介
近年生成對抗網路(GAN)展現出巨大的進展,
尤其是 StyleGAN 已經可生成高解析度的人臉,
大家可以點進這網站看看 - StyleGAN v2 所生成的人臉 - This Person Dose Not Exist
由於 StyleGAN 是透過雜訊來隨機生成人臉,
沒辦法給定一張圖像作為條件(Conditional)來生成特定的人臉,
因此本文提出 Pixel2style2pixel(psp) 來解決此問題。
將輸入圖像作為參考,並透過 StyleGAN v2 生成相似輸入的人臉,
最終達成人臉的圖像轉換效果。

本模型提出利用編碼器(Encoder)來獲得輸入圖像的對應風格特徵(Style code),
將輸入圖像所提取出的風格特徵作為 StyleGAN v2 生成時的風格特徵。
下圖為 StyleGAN v1 的架構圖,本模型的概念是透過將對應風格的特徵取代 A 的位置,
藉此達到 Image-to-Image 圖像轉換的功能。
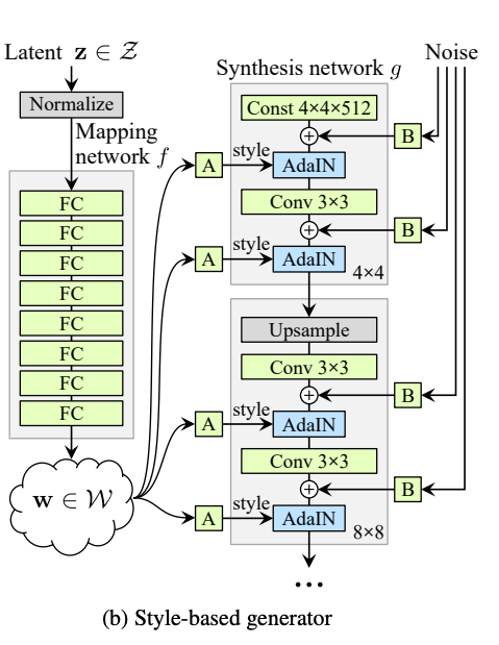
本模型展示了利用不同 Domain/Task(人臉、素描、語意分割)作為輸入並生成高品質之人臉,
目前僅可運用於生成高品質人臉、貓狗轉換以及卡通化(Toonify)的任務,
由於該模型高度仰賴 StyleGAN v2,因此若想實現的任務沒有 StyleGAN v2 的權重,則無法使用此框架。

本模型之限制:
- 需要有對應任務的 StyleGAN 權重,因 StyleGAN 作為 Decoder 掌管了最終輸出的圖片。
- 對空間上是沒有強烈的對應關係,由於轉換風格特徵(Style code)時,是採用 Linear model,因此會丟失空間資訊。
- 預設上是不訓練 StyleGAN 的模型,因訓練 StyleGAN 的訓練成本太過高,雖然在專案中有在探討 Issue #104是否要引入 stylegan2-ada,但論文中沒探討到這點。
- 如 3 所說不訓練 StyleGAN,因此也不需要 Discriminator 進行對抗式學習。
- 訓練編碼器是採用監督式學習,又因為是 Image-to-Image 的任務,因此需要 Pixel-level 的 GT。
Noted: 本簡介在撰寫時,並無明顯區分 StyleGAN 以及 StyleGAN v2,但模型中是使用 StyleGAN v2。
方法
Encoder 架構採用 Feature Pyramid Network(FPN) 的形式,
藉此可較有效的萃取不同 Scale 的特徵。
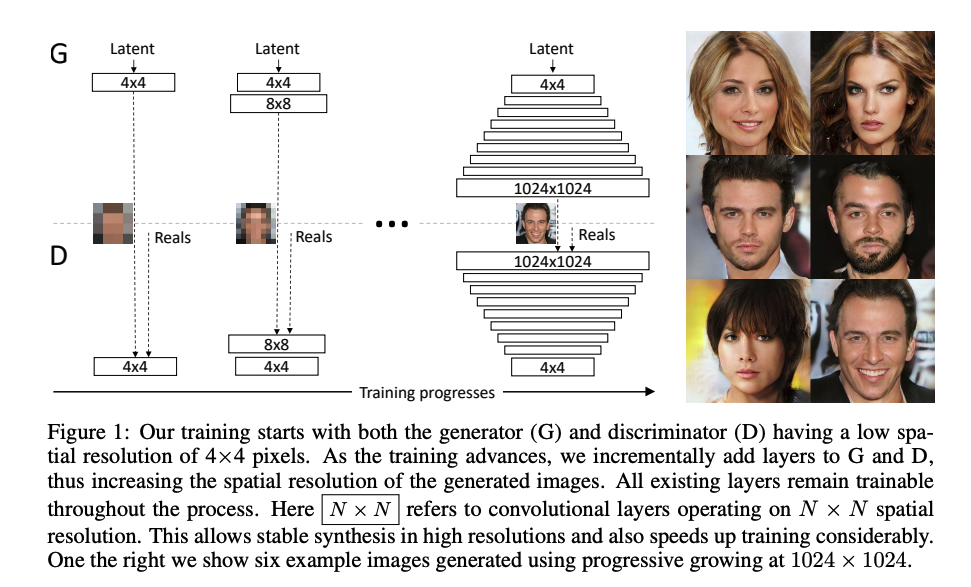
下圖為 Progressive GAN(StyleGAN 所基於的框架),
可看出對於 Progressive GAN 是由不同 Scale 的 Layer 依序訓練而成。
psp 模型藉由 FPN 架構,將不同 Scale 的特徵輸入至對應 Scale 的 StyleGAN,
並將 18 個 Style code(W+)分為三個部分,
依序為 Coarse, Medium and Fine 對應至 StyleGAN 中不同 Scale 的位置。
- Coarse style code: 0 ~ 2 (姿勢、髮型、臉型…)
- Middle style code: 3 ~ 6 (臉部特徵、髮型、眼睛開合…)
- Fine style code: 7 ~ 17 (細微改變,顏色變化)
若對各階層 Style code 的變化感興趣可看此影片 - A Style-Based Generator Architecture for Generative Adversarial Networks 對於 StyleGAN 的 Style Code 有不清楚的可以參考這篇文章:Keywords to know before you start reading papers on GANs
Noted: 以我的實驗更改 Middle style code 的效果最為明顯,有較大的變化。
而本篇主打的另一個特點是,他直接將 Encoder 的輸出作為 Style code(W+)傳入 StyleGAN 就能生成出想要的圖片。
而以往的論文是先找出 Pre-trained StyleGAN 的 W+(Latent code) 各自代表什麼,再經過調整後生成想要的圖片。
因此 Pixel2style2pixel(psp) 的概念是輸入參考圖片後,
基於 Encoder 生成對應的 Style code,
再將 Style code 輸入至 StyleGAN 的對應位置作為 Normalization,
藉此生成不同種類之結果。
寫成公式會變成:
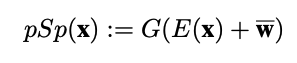
- psp: 本模型 Pixel2style2pixel
- G: StyleGANv2
- E: Encoder
- w: Pretrained styleGAN 的平均 Style code(基於此 Style code 去學習會有比較好的 Initialization)
而我們也可以透過隨機生成 w 至不同位置的 styleGAN 來達到不一樣的結果,
可透過一個參數 α 來評估到底要各自保留多少比例的特徵。
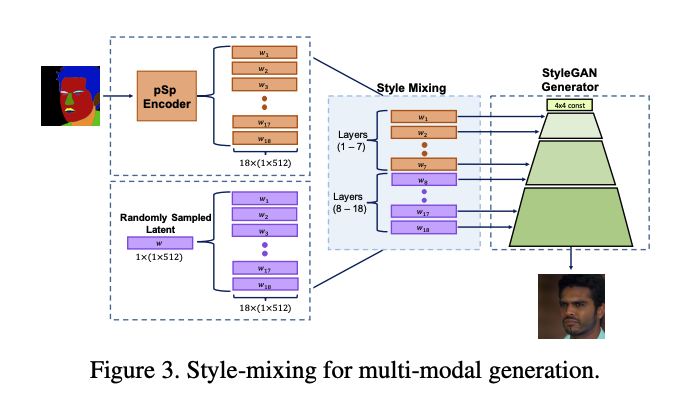
知道整體概念後,來介紹使用到的 Loss funtion。
L2 Loss
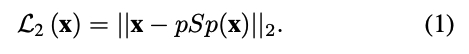
希望生成出來的圖片psp(x),會與輸入圖片(x)相似,這邊用的是 L2 loss,
不過這公式是基於輸入輸出同個 Domain 的情況下,如輸入的是人臉,希望輸出也要是相同的人臉。
但對於不同 Domain 的任務(e.g., 素描任務),訓練時的輸入會是:
- x(素描)
- y(素描對應的人臉圖)
此時就會變成:
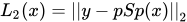
Perceptual Loss
利用已訓練過的神經網路(F)來萃取特徵,希望輸入圖片與生成圖片的特徵圖相似,此處使用 Pretrained AlexNet。
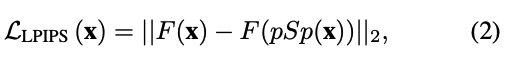
Regularization Loss
希望輸出的 Style code 可以接近 Pretrained styleGAN 的平均 Style code。
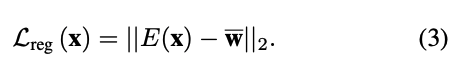
ID Loss
希望輸入圖片與生成圖片的人物特徵相似,此處使用人臉辨識模型 ArcFace network 提取 Embedding,並比對兩者的餘弦相似性 (Cosine similarity)。
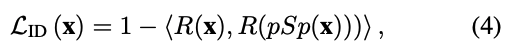
Total Loss
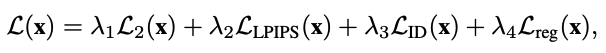
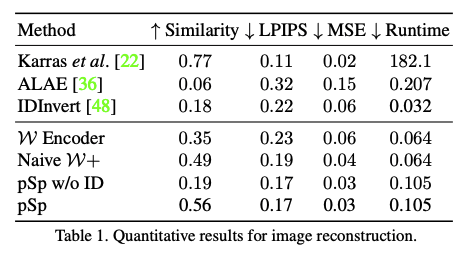
Result





同場加映
剛好我也有試一下結果,給大家看看。

參考資料:
Encoding in Style: a StyleGAN Encoder for Image-to-Image Translation
Progressive Growing of GANs for Improved Quality, Stability, and Variation
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
StyleGANv2: Analyzing and Improving the Image Quality of StyleGAN
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?
A Style-Based Generator Architecture for Generative Adversarial Networks