AutoGen 探索 - 串接常見的 LLM 模型與自建 API 伺服器
在這篇文章中分享了如何利用 AutoGen 有效地整合不同 LLM,如: Openai GPT-4, Azure Openai GPT-4, Gemini, Mistral.ai 等模型,並且展示了如何利用 vllm 與 FastChat 自建 LLM API 伺服器。如果你對AI、LLM、自然語言處理或 API 伺服器搭建感興趣,這篇文章將是一個不錯的閱讀選擇。我詳細介紹了 AutoGen 的靈活性和實用性,以及它如何幫助創建更智能、更個性化的AI應用。
AutoGen 是一個新的 AI 互動框架,透過使用者事先定義出不同 AI 助理,讓他們互動去完成最終任務,未來使用者只需要給定一個命令,AI 助理就會像是公司的職員一樣各司其職互相合作來完成任務,這些 AI 助理可以依據任務去撰寫對應的程式碼,透過開發環境來編譯以及執行程式碼,此外也可結合不同的服務,只要提供相關的文件,他就可以自己去進行 API 串接非常自動化。 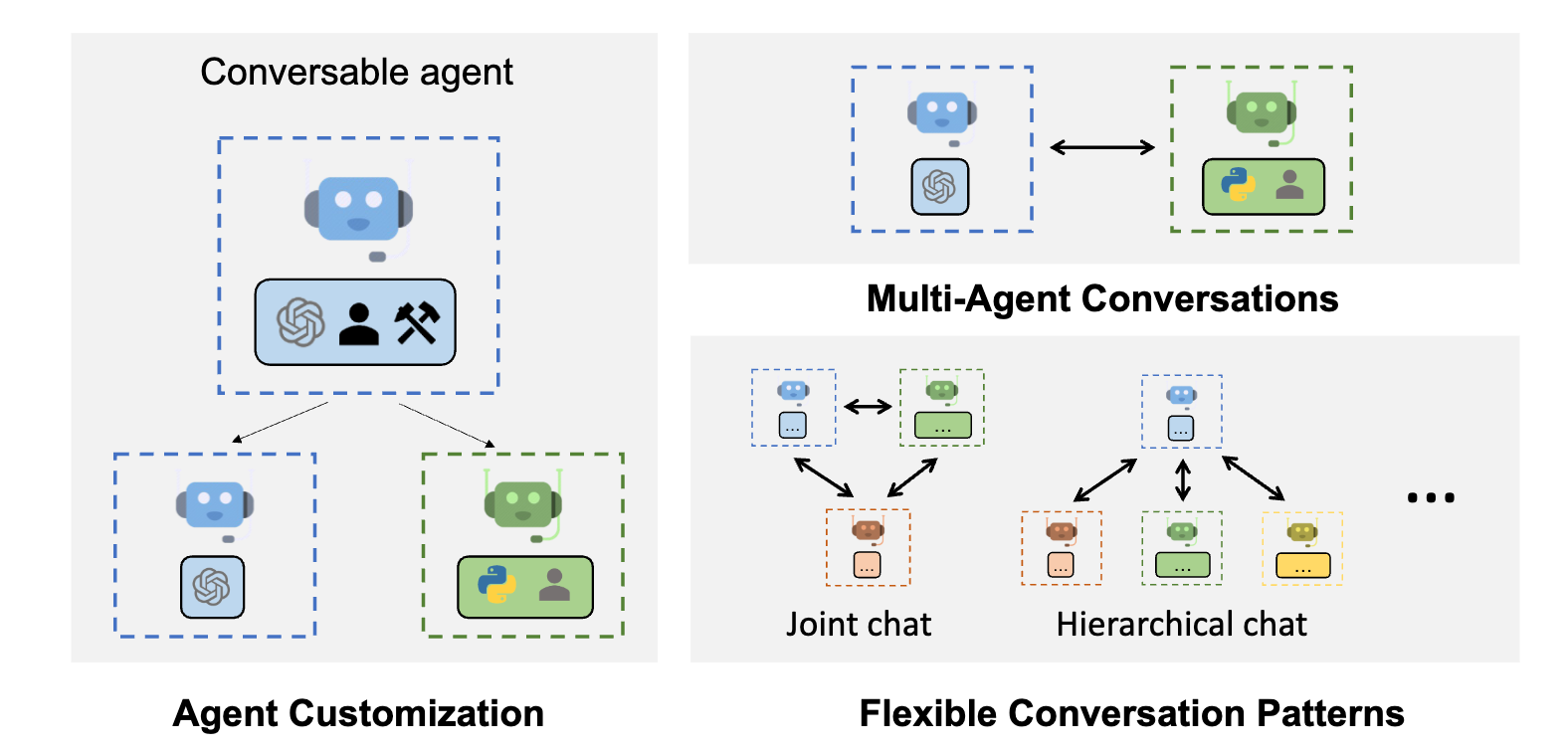
由於不同的 AI 助理都有其擅長的項目,除了可給定對應的 System prompt 之外,也能夠設定對應的 LLM 模型,舉例來說:如果要生成圖片可以使用 DALLE,需要理解圖片可以使用 GPT-4V,如果需要一個擅長繁體中文的 AI 助理,可以使用 MediaTek 所開發的繁中 LLM - Breeze7B,AutoGen 在這當中提供一個彈性的框架來讓使用者可以客製化 AI 助理,並建構出屬於自己的 LLMs 應用。 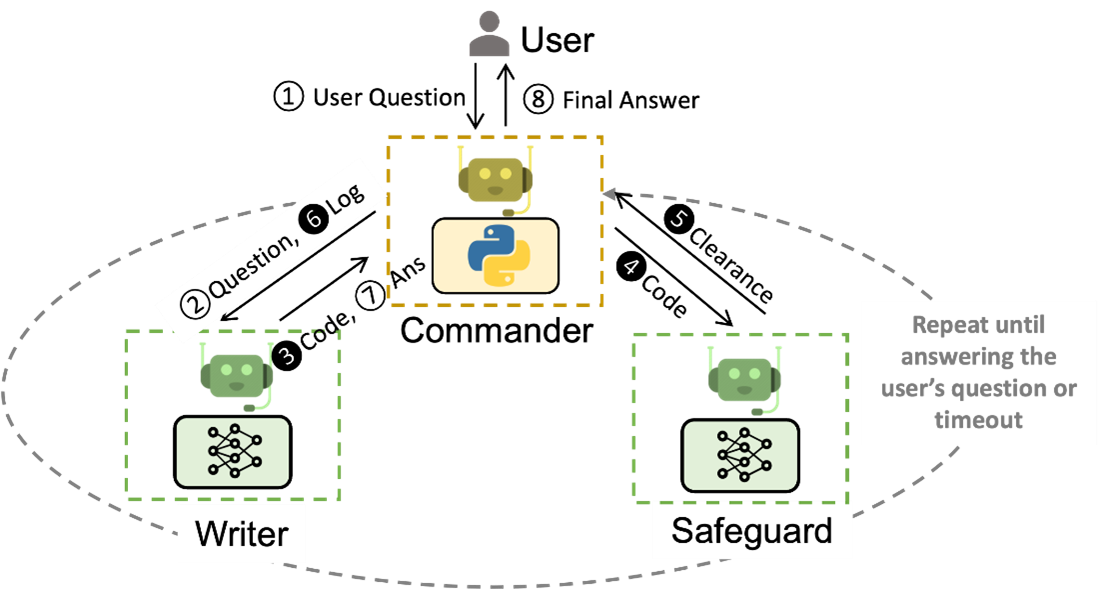
目前有出 AutoGen Studio 讓大家不需要寫程式也可以直接使用 GUI 介面來體會到 AutoGen 的強大,有興趣的人可以去下載來使用,不過本篇教學還是以程式碼的說明為主。 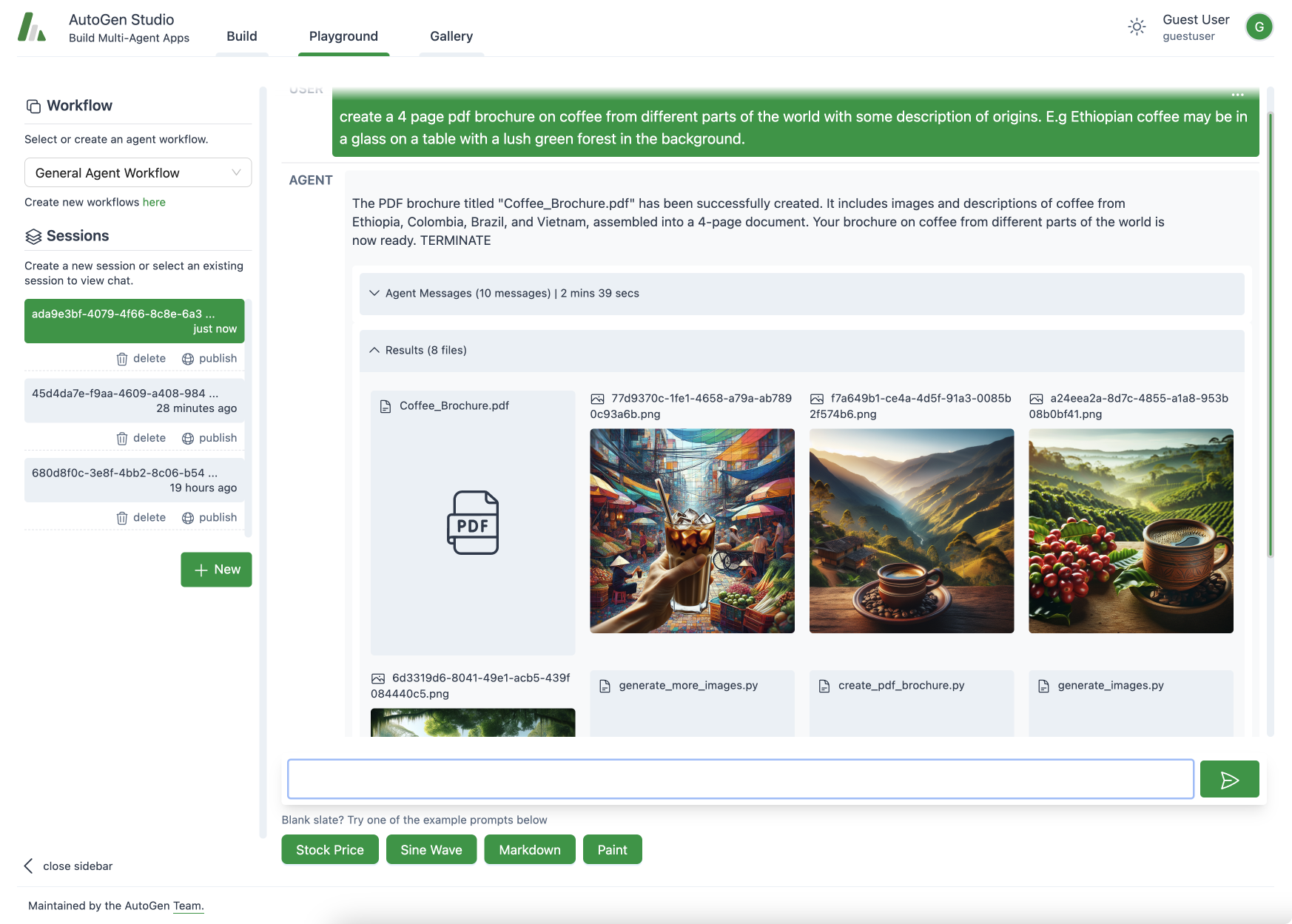
本篇教學使用 AutoGen v0.2.9 版本,由於 AutoGen 持續更新,未來可能會調整相關的使用方式,請依官方文件為主。
本篇 Blog 將涵蓋以下內容:
- AutoGen 官方範例展示(自動寫程式、圖片理解、自動生成圖片並修正)
- AutoGen 串接不同之 LLM 模型(Openai、Azure Openai、Google Gemini、Mistral.ai)
- AutoGen 基礎功能介紹
- AutoGen 特色功能:Agent AutoBuild、Caching、AgentOptimizer
- 如何使用 vllm、FastChat 等工具來架設專屬自己的 LLM Server
AutoGen 官方範例展示
在介紹 AutoGen 的瑣碎設定之前,我想先讓大家來看 AutoGen 官方所提供的範例,來理解 AutoGen 能達成怎樣的任務。
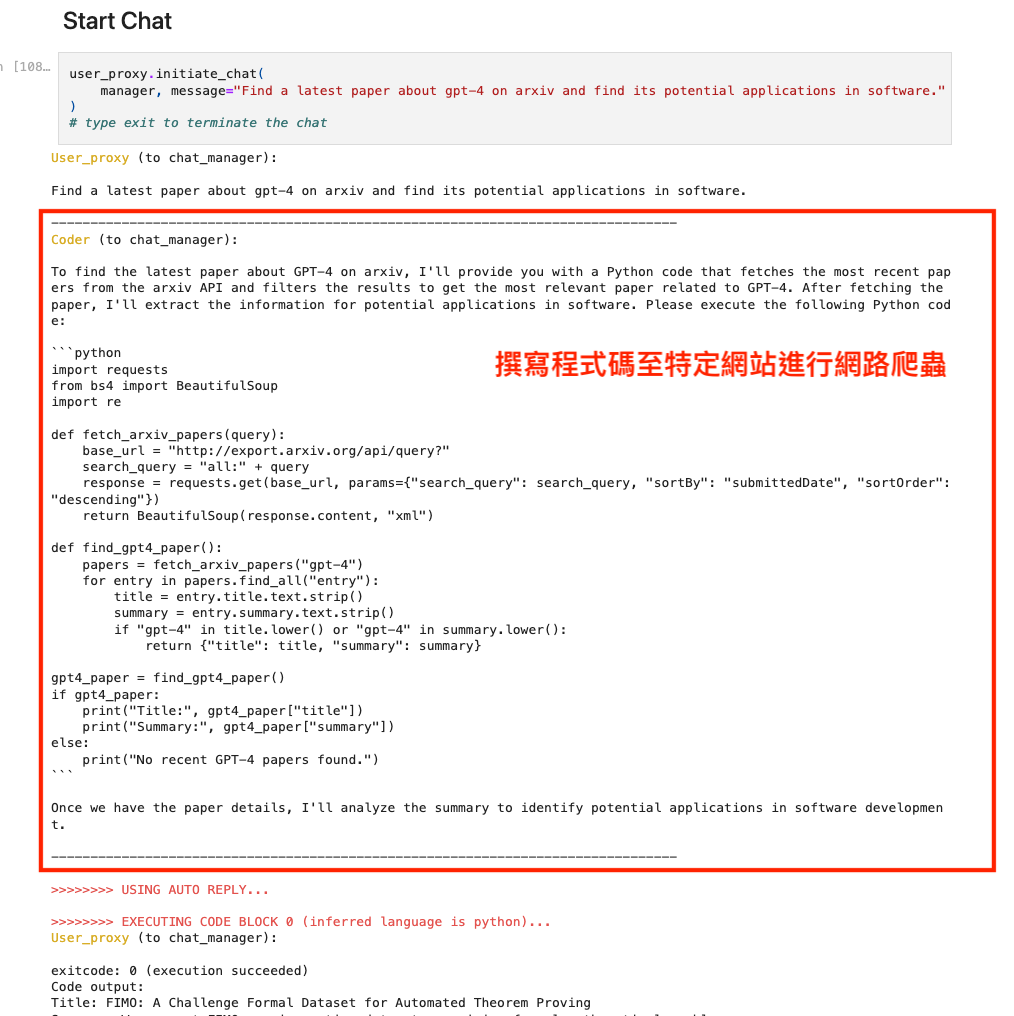
範例1:Find a latest paper about gpt-4 on arxiv and find its potential applications in software.
到 ArXiv 論文網站找出關於 gpt-4 的相關論文,並且說明可延伸的潛在應用。 從下面的例子可以發現,當一切都設定好後,使用者只要發送一個指令,AI助理就會開始理解指令,自己開始寫程式碼並且執行程式碼,最終回傳結果給使用者,一切都是這麼的美好。

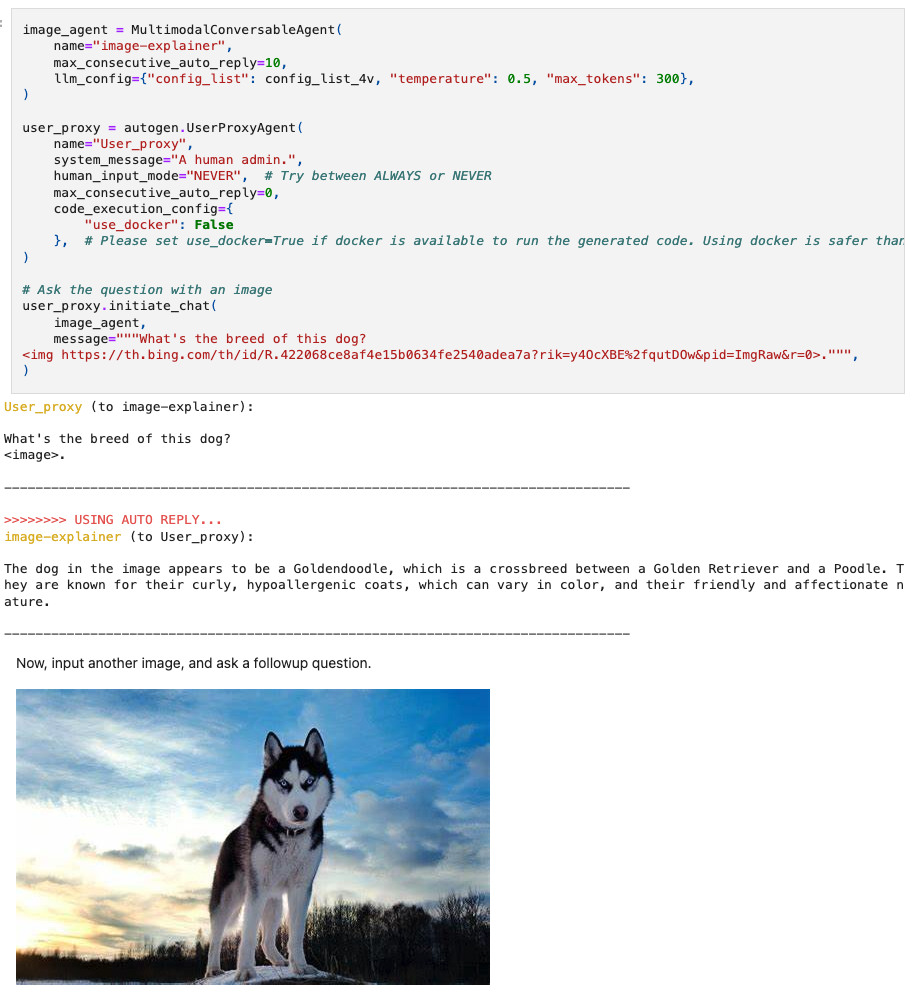
範例2:Agent Chat with Multimodal Models: GPT-4V
結合多模態模型 GPT-4V 來進行互動,透過輸入狗的照片來詢問品種。
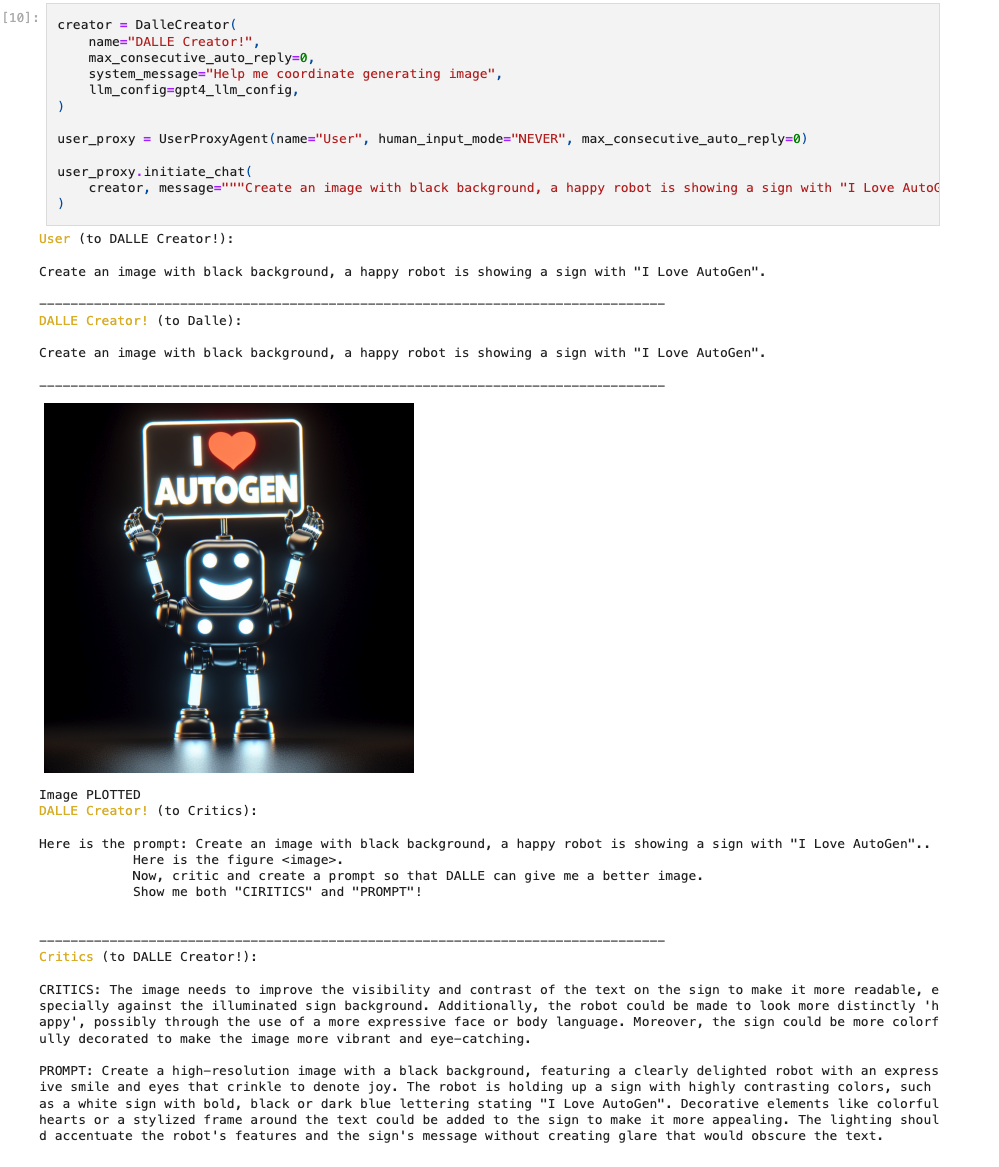
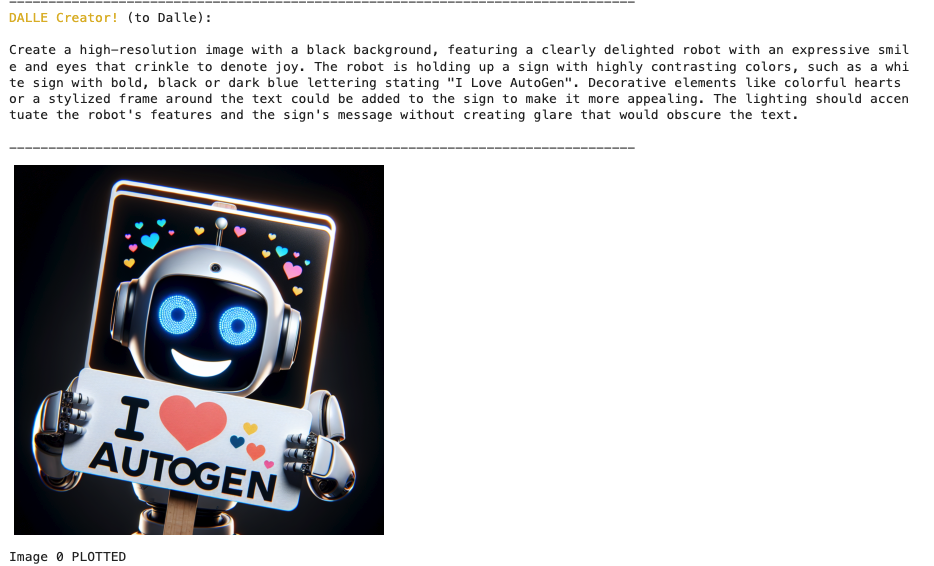
範例3:Agent Chat with Multimodal Models: DALLE and GPT-4V
結合 Dalle 生成圖片並與多模態模型 GPT-4V 來進行互動,Azure DALLE 可以生成圖片,GPT-4V 可以用於給 DALLE 提供意見,來讓生成圖片更符合使用者的描述。
AutoGen 基礎使用介紹
下方將用 Google Colab 進行示範,也可以使用 Jupyter Notebook,第一步是要安裝 AutoGen
!pip install pyautogen
AutoGen 步驟可簡單分成以下三步:
- 設定 LLM API Key
- 設定使用者代理與 AI 助理
Autogen 使用 GroupChat 來讓多個 AI 助理來共同解決一個問題。會有一個總經理的角色來選擇要讓哪個 AI 助理處理任務,過程中總經理會不斷依據目前的任務進度來決定要由誰來執行下一步任務,直到完成任務。
- 發送指令
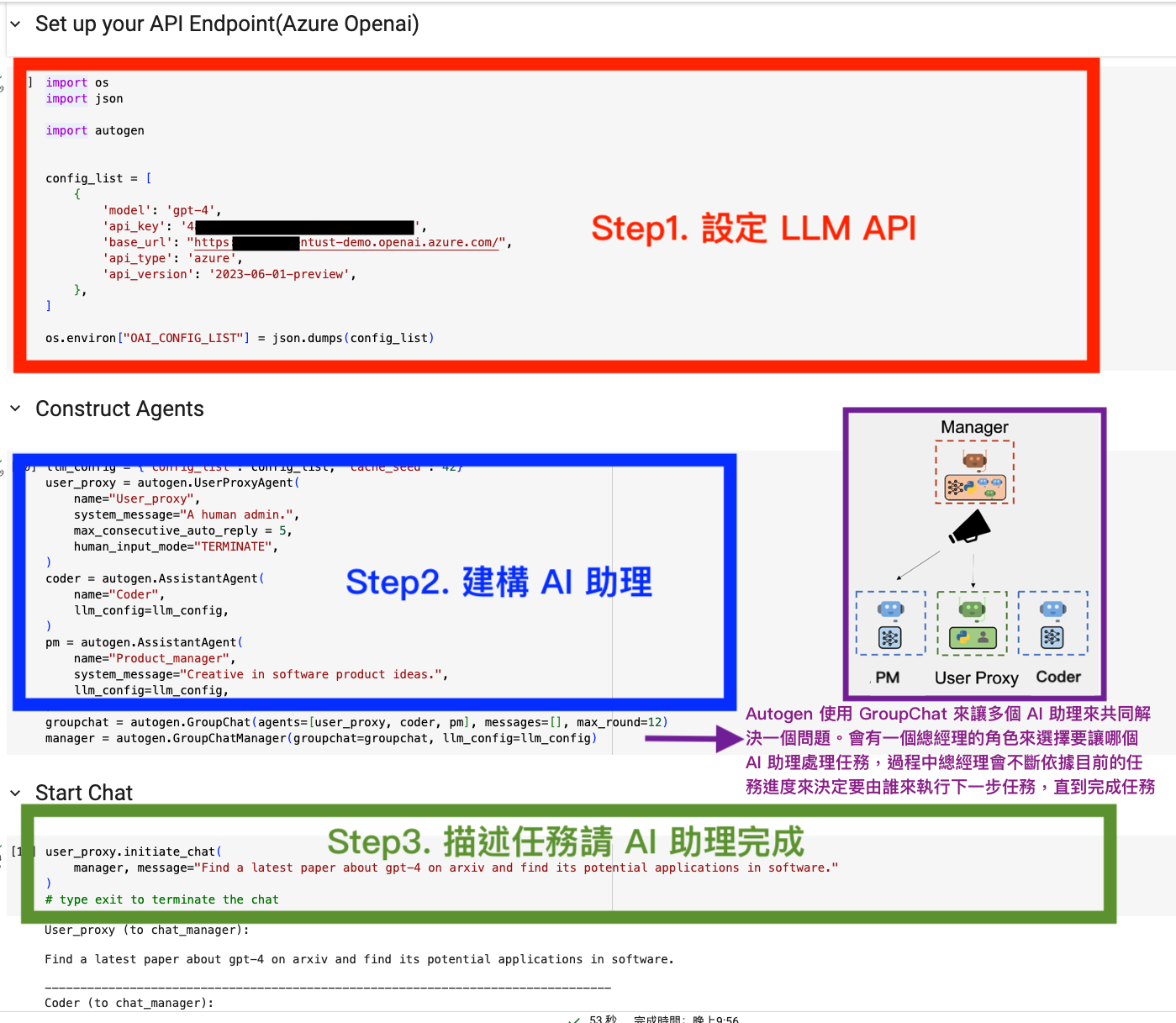
1. 設定 LLM API Key
因為 AutoGen 需透過 API 的方式與 LLM 進行串接,我列出以下四個 LLM API key 供各位參考,當然除了下方的 LLM API 之外,你可以選擇使用自己的伺服器搭建 LLM,這也將在本篇的後半部會提到。
- 申請 Openai API Key(需綁定信用卡)
- 申請 Microsoft Azure openai
專門服務企業,一般使用者應該難以申請 如果台灣企業有需要可以去找 CloudRiches 雲馥數位股份有限公司協助申請
- 申請 Google Gemini Pro API Key(免費)
Gemini Ultra 程度大概是 OpenAI GPT-4; Gemini Pro 則是 OpenAI GPT-3.5 能力偏差,需要更多次的詢問才有正確答案。 不推薦:LLM 能力偏弱,難以回答複雜指令且 AutoGen 與 Gemini 之整合較差,需要額外的步驟進行安裝。
- 申請 mistral.ai(需綁定信用卡)
目前 mistral.ai 沒辦法正常使用 AutoGen 的群組功能,因此難以讓多個 AI 助理互相協作,可關注此 Issue#991: [Feature Request]: Support for Mistral AI API (and Mixtral2),未來若該問題修復,會再嘗試該 LLM 之成效。
首先要設定好一個檔案 OAI_CONFIG_LIST,大致會長這樣,下方會示範如何透過程式碼來創建這個文件,依據不同的 API Key 會有些微不同的寫法。
[
{
"model": "gpt-4",
"api_key": "<your OpenAI API key here>"
},
{
"model": "<your Azure OpenAI deployment name>",
"api_key": "<your Azure OpenAI API key here>",
"base_url": "<your Azure OpenAI API base here>",
"api_type": "azure",
"api_version": "2023-07-01-preview"
},
{
"model": "<your Azure OpenAI deployment name>",
"api_key": "<your Azure OpenAI API key here>",
"base_url": "<your Azure OpenAI API base here>",
"api_type": "azure",
"api_version": "2023-07-01-preview"
}
]
Openai API Key 串接示範
import os
import json
import autogen
config_list = [
{
'model': 'gpt-4',
'api_key': '<your OpenAI API key here, sk-xxxxx>',
},
]
os.environ["OAI_CONFIG_LIST"] = json.dumps(config_list)
Azure Openai API Key 串接示範
import os
import json
import autogen
config_list = [
{
'model': 'gpt-4',
'api_key': '<your Azure OpenAI API key here>',
'base_url': "<your Azure OpenAI API base here>",
'api_version': '2023-06-01-preview',
'api_type': 'azure',
},
]
os.environ["OAI_CONFIG_LIST"] = json.dumps(config_list)
Google Gemini API Key 串接示範
# Need to install a specific version that supports Gemini
!pip install https://github.com/microsoft/autogen/archive/gemini.zip
!pip install "google-generativeai" "pydash" "pillow" "pydantic==1.10.13"
!pip install "pyautogen[gemini]"
import os
import json
import autogen
config_list_gemini = [
{
'model': 'gemini-pro',
'api_key': '<your Gemini API key here>',
"api_type": "google"
},
]
Mistral.ai API Key 串接示範
import os
import json
import autogen
config_list = [
{
'model': 'mistral-medium',
'api_key': '<your Mistral AI API key here>',
'base_url': "https://api.mistral.ai/v1/",
},
]
os.environ["OAI_CONFIG_LIST"] = json.dumps(config_list)
設定使用者代理與 AI 助理並發送請求
Example 1. 建立一個 AI 助理進行互動,以及創建一個使用者 UserProxyAgent 來設定如何互動,此處會要求 AI 助理寫出基本的氣泡排序法,並且要有 Python 以及 Rust 的版本。
# Install the Library
# !pip install pyautogen
import os
import json
import autogen
# Set up your API Endpoint(Azure Openai)
config_list = [
{
'model': 'gpt-4',
'api_key': '<your Azure OpenAI API key here>',
'base_url': "<your Azure OpenAI API base here>",
'api_version': '2023-06-01-preview',
'api_type': 'azure',
},
]
os.environ["OAI_CONFIG_LIST"] = json.dumps(config_list)
# Create a user agent
user = autogen.UserProxyAgent("user proxy",
human_input_mode="ALWAYS")
# Create an assistant agent
assistant = autogen.AssistantAgent(
"assistant",
system_message="You are a friendly AI assistant.",
llm_config={"config_list": config_list},
)
# Start the conversation
user.initiate_chat(assistant, message="Write a program in Python and Rust that Sort the array with Bubble Sort: [1, 5, 2, 4, 2]")
常見參數說明:
- UserProxyAgent: 定義使用者的設定。
- 欄位:name 設定角色名稱 e.g., Admin
- 欄位:system_message, 對角色進行描述
e.g., Reply TERMINATE if the task has been solved at full satisfaction. Otherwise, reply CONTINUE, or the reason why the task is not solved yet.
- 欄位:human_input_mode, 設定是否需要參與互動
“NEVER”: 全自動直到任務完成 “ALWAYS”: 每次 AI 助理回答都要互動 “TERMINATE”:當 AI 助理認為任務結束或是對話次數超出上限時,會詢問使用者是否繼續。
- 欄位:code_execution_config, 可設定是否自動執行回傳的程式碼。
目前是預設會將程式碼自動執行於 Docker,也可設定不要自動執行回傳之程式碼。
- 欄位:is_termination_msg,用來確認回傳 AI 助理回傳的訊息是不是代表任務結束了,通常都是下方的寫法
e.g., lambda x: x.get(“content”, “”) and x.get(“content”, “”).rstrip().endswith(“TERMINATE”),
- AssistantAgent: 定義AI助理,每個助理都可以設定獨特的角色,來提供資訊或根據其配置和接收到的輸入執行特定操作。角色可能是:產品經理、UI、工程師和複查員等等。
- 必填欄位:llm_config, 設定 LLM 相關 API Keys
- 欄位:name, 設定角色名稱 e.g., PM, Coder
- 欄位:system_message, 對角色進行描述 e.g., Creative in software product ideas.
- 欄位:function_map, 可以去呼叫特定 Function 實現更複雜的功能,這邊較為複雜,可參考:agentchat_video_transcript_translate_with_whisper.ipynb
Example 2. 到 ArXiv 論文網站找出關於 gpt-4 的相關論文,並且說明可延伸的潛在應用。 在這個任務中,可以把自己想像成是總經理,並且定義好兩個AI助理,分別是 Coder 以及 PM 這兩位 AI 助理(Assistant)會自己來執行任務,Coder 會自動寫程式來對特定網站進行爬蟲,獲得論文的內容,PM 則會基於論文的內容來將未來可能的應用進行梳理,並完成報告。接著將這幾個 AI 助理(Coder, PM)一起放到一個群組方便他們內部進行溝通。
# Install the Library
# !pip install pyautogen
import os
import json
import autogen
# Set up your API Endpoint(Azure Openai)
config_list = [
{
'model': 'gpt-4',
'api_key': '<your Azure OpenAI API key here>',
'base_url': "<your Azure OpenAI API base here>",
'api_version': '2023-06-01-preview',
'api_type': 'azure',
},
]
os.environ["OAI_CONFIG_LIST"] = json.dumps(config_list)
llm_config = {"config_list": config_list, "cache_seed": 42}
# Create a user agent
user_proxy = autogen.UserProxyAgent(
name="User_proxy",
system_message="A human admin.",
human_input_mode="TERMINATE",
)
# Create the assistant agents
coder = autogen.AssistantAgent(
name="Coder",
llm_config=llm_config,
)
pm = autogen.AssistantAgent(
name="Product_manager",
system_message="Creative in software product ideas.",
llm_config=llm_config,
)
# Start the conversation
groupchat = autogen.GroupChat(agents=[user_proxy, coder, pm], messages=[], max_round=12)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config=llm_config)
user_proxy.initiate_chat(
manager, message="Find a latest paper about gpt-4 on arxiv and find its potential applications in software."
)
他們的互動流程如下:
- 總經理(使用者)發送任務指令:請到 ArXiv 論文網站找出關於 gpt-4 的相關論文,並且說明他可延伸的潛在應用
- Coder(AI助理):收到指令開始寫了一個 Python 的爬蟲程式,可以爬取 ArXiv 網站內容,並自動篩選出標題中包含 GPT-4 的論文
- 總經理(使用者):收到程式碼,自動執行程式獲得論文內容,並將內容交給 PM
- PM(AI助理):基於論文內容去做不同面向的摘要,生成出一份報告,並將報告交給總經理
- 總經理(使用者):收到報告。
從上面的例子可以發現,只要設定完 AI 助理後,使用者只要發送一個指令,AI助理就會開始理解指令,自己開始寫程式碼並且執行程式碼,最終回傳結果給使用者,一切都是這麼的美好,簡單的使用情境示範到這邊,也算是對 Autogen 有初步的認識了。
AutoGen 特色功能
Agent AutoBuild 在過去我們創建 AI 助理時,需要先思考這個任務會需要哪些角色,並創建對應的 AI 助理並且對他進行 System message 的描述,(如下圖左),缺點是如果任務更換的話,現有的 AI 助理不見得能滿足需求。 現在 Autogen 提供新的功能 AutoBuild 讓使用者可以描述想要達成的任務,接著就會自動的創建需要的 AI 助理並且為他們填寫適當的 System message,(如下圖右),讓整個 AI 互動框架更加的智慧且彈性。
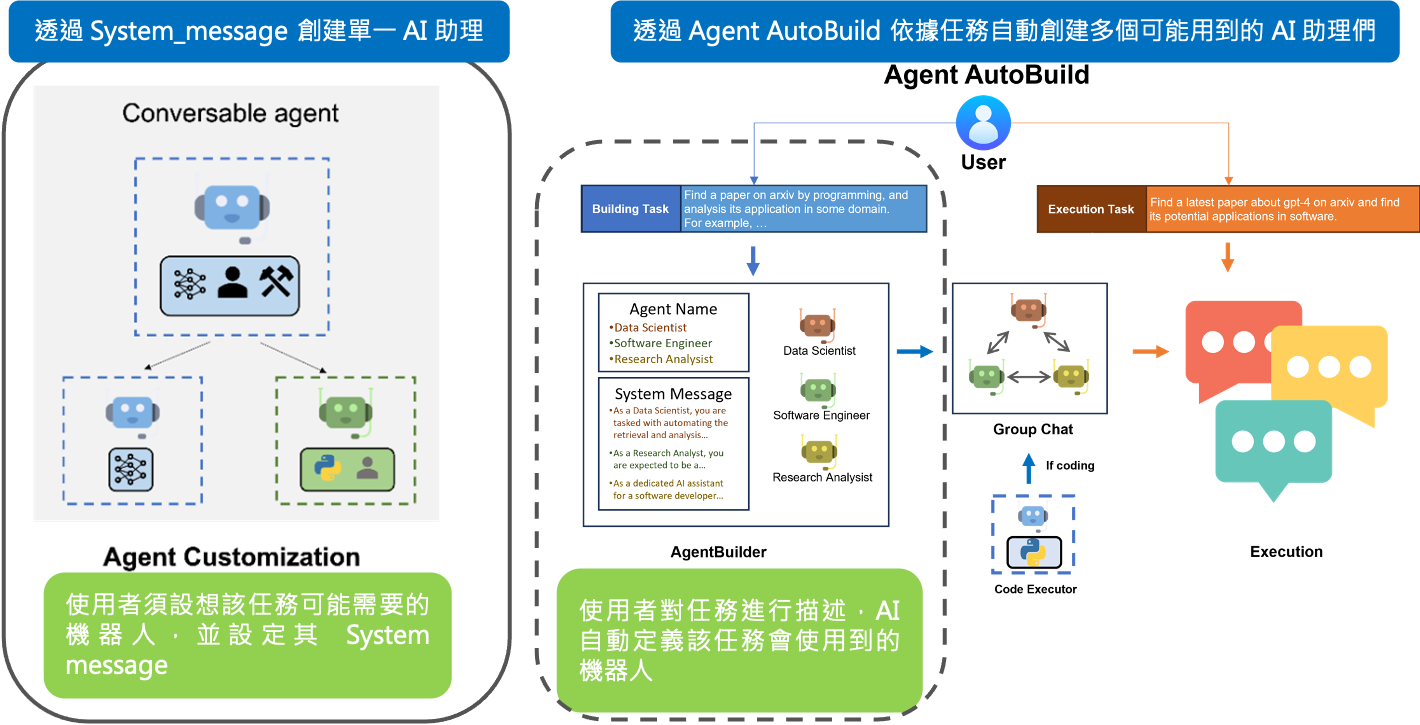
- Caching 當有問題頻繁被詢問時,可以透過 Cache 來重複使用之前的回答,節省成本。用法很簡單,如下:
# Use DiskCache as cache with Cache.disk() as cache: user.initiate_chat(assistant, message=<your message>, cache=cache) - AgentOptimizer 相較於傳統的 ML 模型,通常都需要透過梯度下降來調整模型的參數,但在 LLM 這種量級的模型,雖然能透過 LoRA 等 parameter efficient fine tuning 的方式只微調少量的參數,但這仍然需要相當大的運算資源才能進行訓練。而 AgentOptimizer 提出在不調整模型參數,僅透過 AI 助理新增適當的 Function call 來將整體的效能改進,舉例來說收集了 100 個對話的歷史紀錄作為訓練資料,我們透過新增或修改 Functions 來評估我們的 AI 助理是否在這 100 個對話中能有更好的成果,希望能藉此改善整體的回答能力,不過這邊還是概念驗證的階段,有興趣的人再試試看。
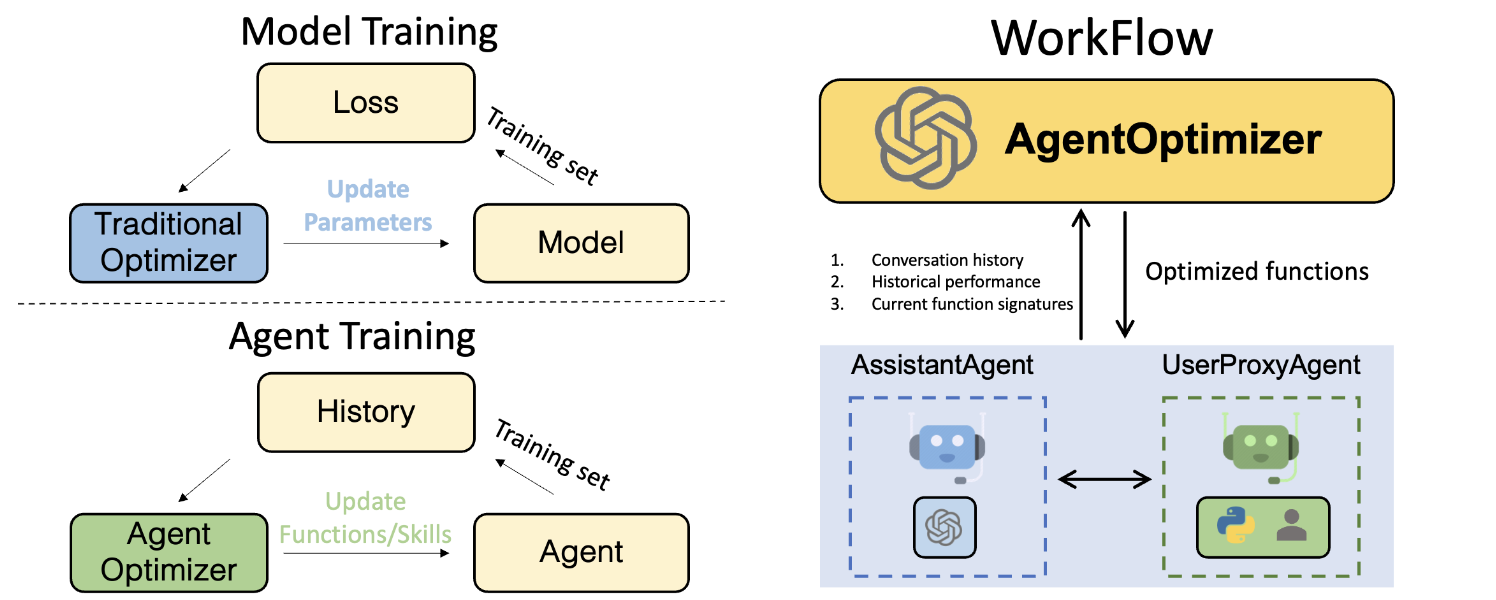
架設專屬自己的 LLM Server
在網路上有許多專案能讓人快速搭建 LLM 伺服器。本文將介紹 vLLM 和 FastChat 這兩個專案,它們所搭建的 API 伺服器與 Openai 所提供的 API接口相似。由於大部分的 LLM 應用都是基於 Openai 的 API 接口所設計的,因此與 Openai 兼容的 API 伺服器,能讓我們可以更容易地整合 AutoGen與其他應用。
此外這些專案都可以輕易地串接 HuggingFace 所開源的 LLM 模型,因此未來大家不管是要使用 vicuna-7b、LLaMA-2、或者是繁體中文的 MediaTek-Research/Breeze-7B 等模型都相當方便。
下方所介紹的範例會需要佔用 GPU VRAM 13~15 GB左右,我的裝置是:
- OS: ubuntu 22.04
- GPU: NVIDIA GeForce RTX 3090(24GB)
- NVIDIA DRIVER: 535.154.05
- CUDA Version: 12.2
vllm
vllm 是一個快速且易於使用的 LLM 推理和服務庫,這是我用過最易於架設的 LLM API Server,只需要一個指令就可以啟動。美中不足的是目前該專案在 GPU 內存的處理還有點問題,舉例來說同等的模型我可以使用 FastChat 成功部署,但使用 vllm 卻會跳出 Try increasing gpu_memory_utilization when initializing the engine. 的錯誤訊息,不過這個問題未來應該都會得到修復,因此推薦大家可以優先嘗試這個專案,我後續也會介紹可以嘗試下一些量化的指令來降低模型 GPU 的使用量。
安裝套件並部署 LLM - facebook/opt-125m
!pip install vllm
python -m vllm.entrypoints.openai.api_server --model facebook/opt-125m
成功執行的畫面如下 
可以透過以下指令確認是否有正確啟動模型:
curl http://localhost:8000/v1/models

接著只要將連線的 config 改為你對應主機 IP 即可讓 AutoGen 連到該 LLM Server
config_list = [
{
'model': 'facebook/opt-125m',
'base_url': "{your hosting server}:8000/v1/",
},
]
下方介紹如何更換成其他 LLM 的模型,主要是更改指令後方的模型,舉例來說我要對應模型改成繁體中文的 MediaTek-Research/Breeze-7B-Instruct-64k-v0_1 的設置方式
# python -m vllm.entrypoints.openai.api_server --model {HuggingFace LLM}
python -m vllm.entrypoints.openai.api_server --model MediaTek-Research/Breeze-7B-Instruct-64k-v0_1
# if you receive an error message "ValueError: No available memory for the cache blocks. Try increasing `gpu_memory_utilization` when initializing the engine."
python -m vllm.entrypoints.openai.api_server --model MediaTek-Research/Breeze-7B-Instruct-64k-v0_1 --dtype auto --gpu-memory-utilization 0.95 --max-model-len 4096
FastChat
FastChat 主要用於訓練、推論、與評估大型語言模型的專案,在這個專案可以快速的與 LLM 進行互動,不過要架設 API-Server 的難度稍高,需熟悉 Docker 的使用,我下方會提供我的設置給大家,希望可以讓大家少走一點坑。
首先要先下載 Repo 並切換至 docker 的目錄,之後啟動 Docker compose。
git clone https://github.com/lm-sys/FastChat.git
cd FastChat/docker
docker compose up
如果順利啟動的話,會像這樣: 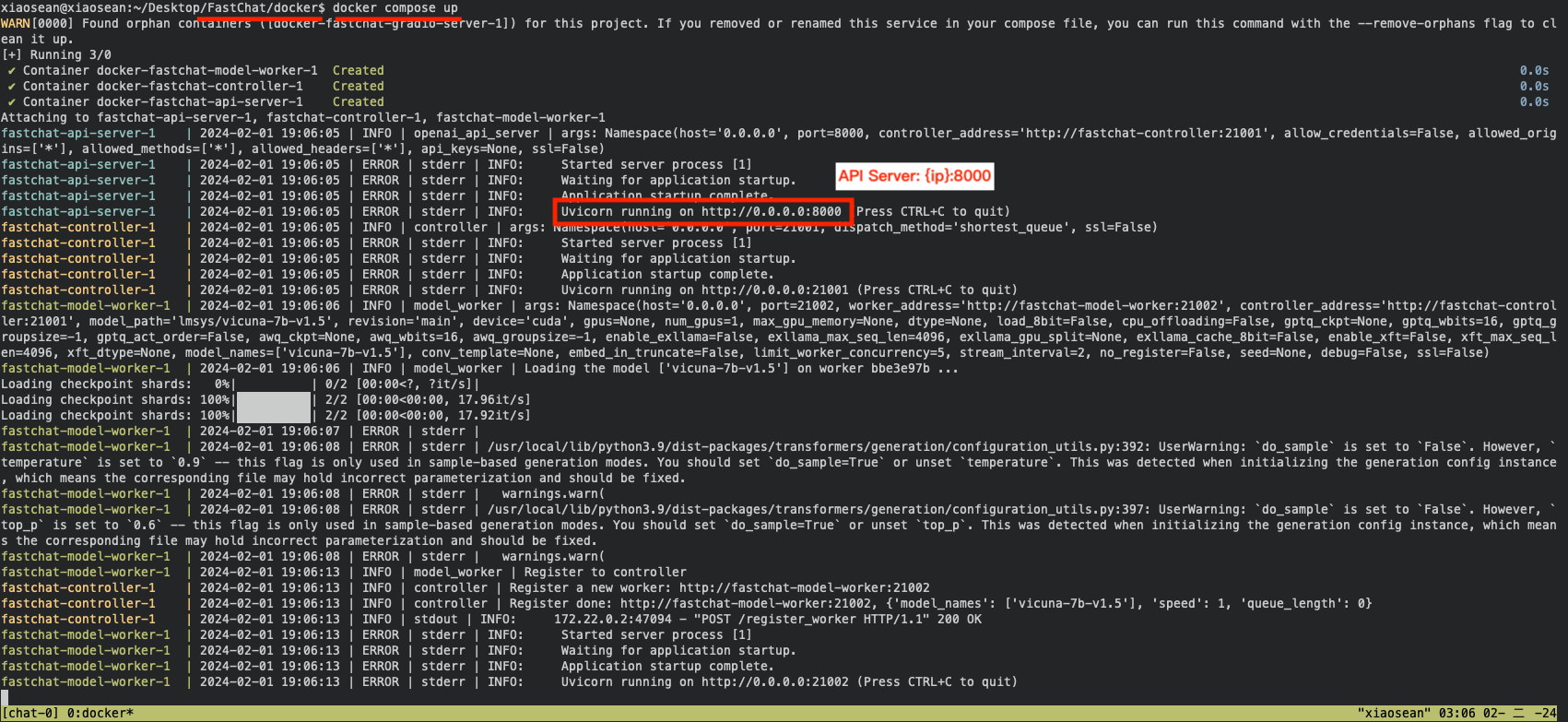
可以透過以下指令確認是否有正確啟動模型:
curl http://localhost:8000/v1/models
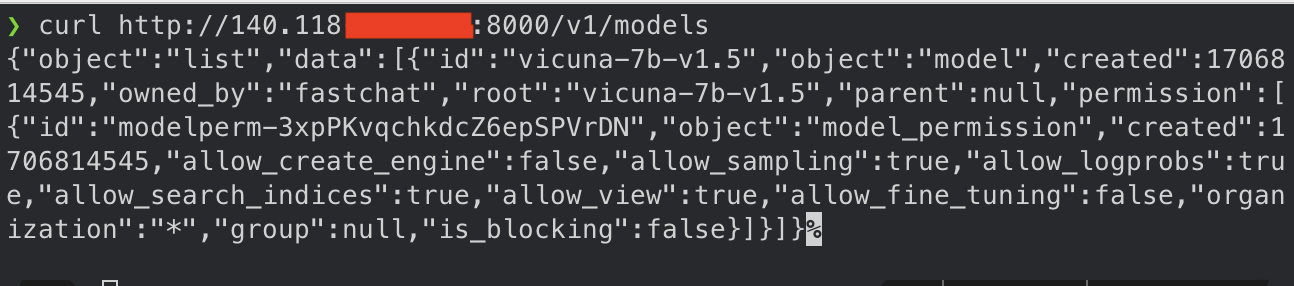
接著只要將連線的 config 改為你對應主機 IP 即可讓 AutoGen 連到該 LLM Server
config_list = [
{
'model': 'vicuna-7b-v1.5',
'base_url': "{your hosting server}:8000/v1/",
},
]
下方介紹如何更換成其他 LLM 的模型,主要是更改 docker-compose.yml 中,fastchat-model-worker 下的 entrypoint 這一行。
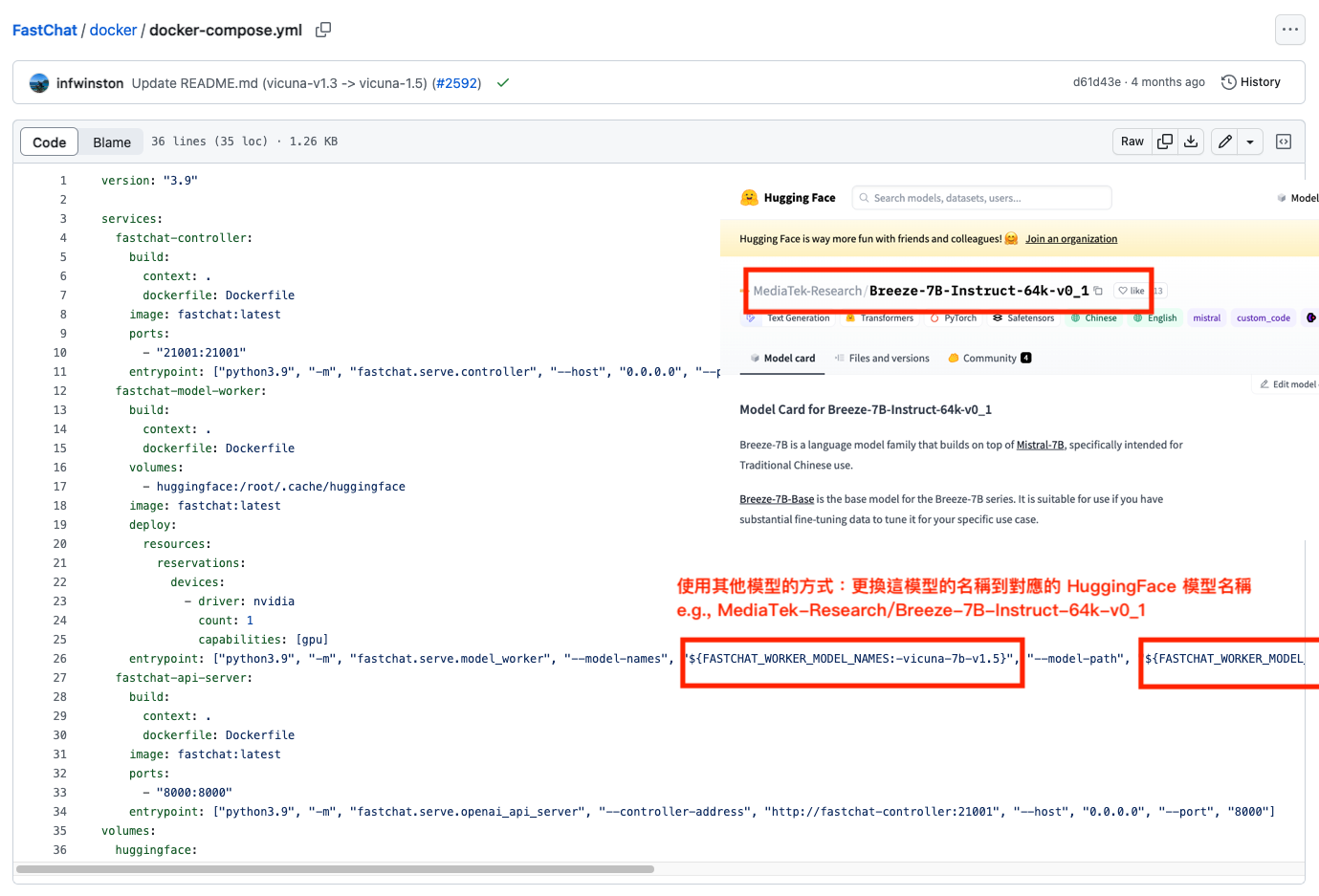
我在下方提供我將對應模型改成繁體中文的 MediaTek-Research/Breeze-7B-Instruct-64k-v0_1 的設置方式,並且有新增 Gradio Web Server 的開啟方式供各位參考,同時因為該模型需要安裝另外的套件,因此也需要修改 Dockerfile。
# docker-compose.yml
version: "3.9"
services:
fastchat-controller:
build:
context: .
dockerfile: Dockerfile
image: fastchat:latest
ports:
- "21001:21001"
entrypoint: ["python3.9", "-m", "fastchat.serve.controller", "--host", "0.0.0.0", "--port", "21001"]
fastchat-model-worker:
build:
context: .
dockerfile: Dockerfile
volumes:
- huggingface:/root/.cache/huggingface
image: fastchat:latest
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# Revise here!!
entrypoint: ["python3.9", "-m", "fastchat.serve.model_worker", "--model-names", "MediaTek-Research/Breeze-7B-Instruct-64k-v0_1", "--model-path", "MediaTek-Research/Breeze-7B-Instruct-64k-v0_1", "--worker-address", "http://fastchat-model-worker:21002", "--controller-address", "http://fastchat-controller:21001", "--host", "0.0.0.0", "--port", "21002"]
fastchat-api-server:
build:
context: .
dockerfile: Dockerfile
image: fastchat:latest
ports:
- "8000:8000"
entrypoint: ["python3.9", "-m", "fastchat.serve.openai_api_server", "--controller-address", "http://fastchat-controller:21001", "--host", "0.0.0.0", "--port", "8000"]
# If you want to set up the gradio web server
fastchat-gradio-server:
build:
context: .
dockerfile: Dockerfile
image: fastchat:latest
ports:
- "8001:8001"
entrypoint: ["python3.9", "-m", "fastchat.serve.gradio_web_server", "--controller-url", "http://fastchat-controller:21001", "--host", "0.0.0.0", "--port", "8001", "--model-list-mode", "reload"]
volumes:
huggingface:
# Dockerfile
FROM huggingface/transformers-pytorch-gpu
RUN apt-get update -y && apt-get install -y python3.9 python3.9-distutils curl
RUN curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py
RUN python3.9 get-pip.py
RUN pip3 install fschat
RUN pip3 install fschat[model_worker,webui] pydantic==1.10.13
RUN pip3 install transformers torch accelerate
RUN pip3 install packaging ninja
RUN pip3 install flash_attn
如果順利執行,可以透過 port: 8001 連線至 Gradio Server 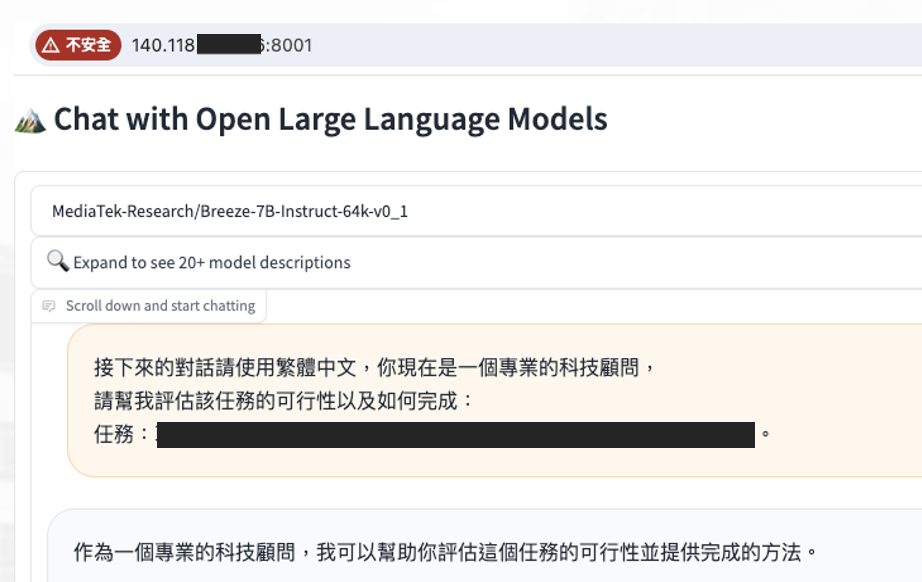
結論
Autogen 是我近期看到最有潛力的工具,它能將 LLM 整合並開發出多元的應用。透過其 Automated Multi Agent Chat 功能,來結合不同專長的 AI 助理共同完成任務。Autogen 還包括多種應用案例,如程式碼生成、執行與調試、多代理協作、網路搜尋、數據可視化、自然語言處理到 SQL 查詢轉換等。它還支援與人類的互動,並且可以透過聊天教導 AI 助理新技能。總的來說,Autogen 的這些特點和功能使其成為一個非常有潛力的框架,能夠加速 LLM 應用到各個不同的領域。