基於Attention之NLP paper - Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin, “Attention Is All You Need”arXiv:1706.03762
NIPS 2017 paper
此篇為NLP相關的大作,
是由Google在2017年6月提出,
而說到這篇論文大家都會與Facebook提出的的convseq2seq做討論。
在閱讀此篇之前,如果對NLP不熟的人可以先看下方這個連結,
尤其是在Seq2Seq的部分,需要了解才能知道這篇的突破在哪。
雷锋网完全图解RNN、RNN变体、Seq2Seq、Attention机制
我看這篇主要是因為有使用到Attention,
而且2018年5月Ian Goodfellow等人提出Self-Attention Generative Adversarial Networks,
那篇的Attention架構和這篇論文的Attention其實是有點相似的,
所以我才來看這篇。
題外話:
我有寫一篇SA-GAN 介紹 - Self-Attention Generative Adversarial Networks,
如何會好奇電腦視覺如何在CNN中使用Attention的人可以看看。
簡介
以往機器翻譯的任務都仰賴RNN或是CNN,
而這篇Paper而是透過Attention的機制,
就達到了當時最高的準確度(( 截至2017年5月。
Attention優點
解決了句子過長時,單字間的的相關性會學不好,以往的模型在這個狀況都處理得不好。
節省整體的計算效能,相較於RNN的模型。
可以平行化計算
題外話:
這篇大家也常常爭論說這篇paper的title下得太狂,
title : Attention Is All You Need。
因為很多概念和做法其實是從CNN那邊來的,
而且也不知道如果結合CNN或是RNN會不會能有更好的結果,
對這件事有興趣的話,可以至這個post看看 如何理解谷歌团队的机器翻译新作《Attention is all you need》?
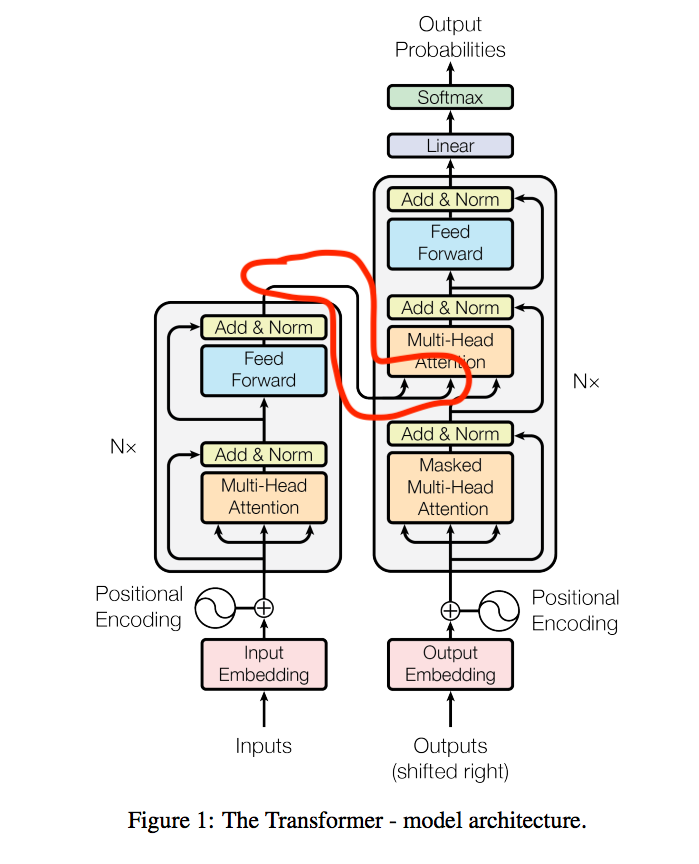
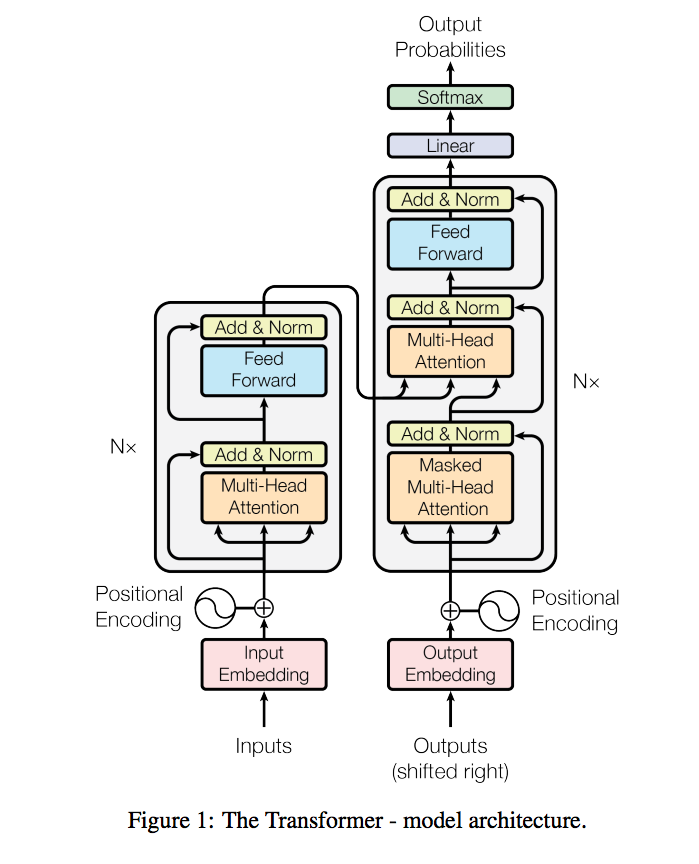
架構
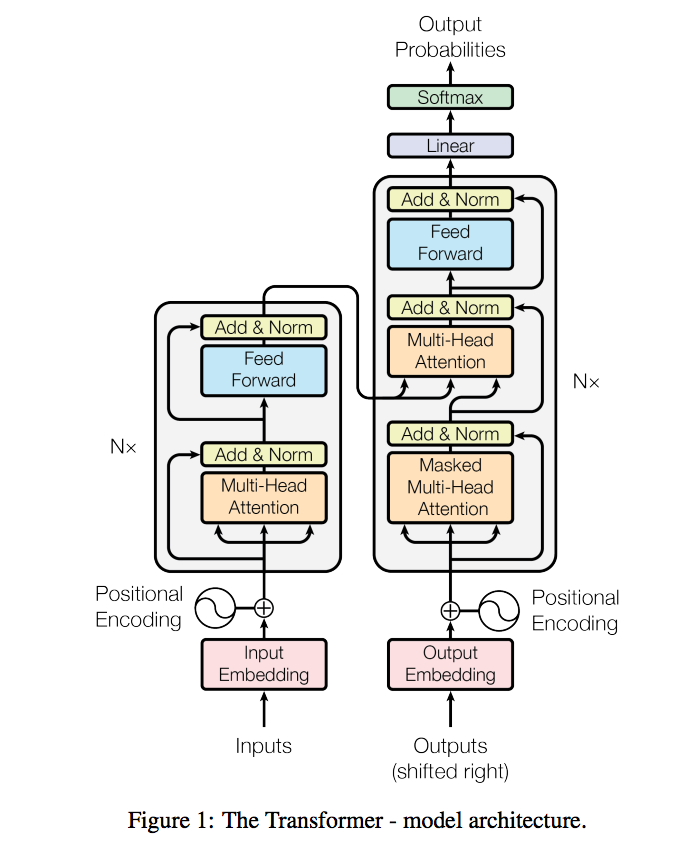
Input / Output
首先要先了解Input / Output
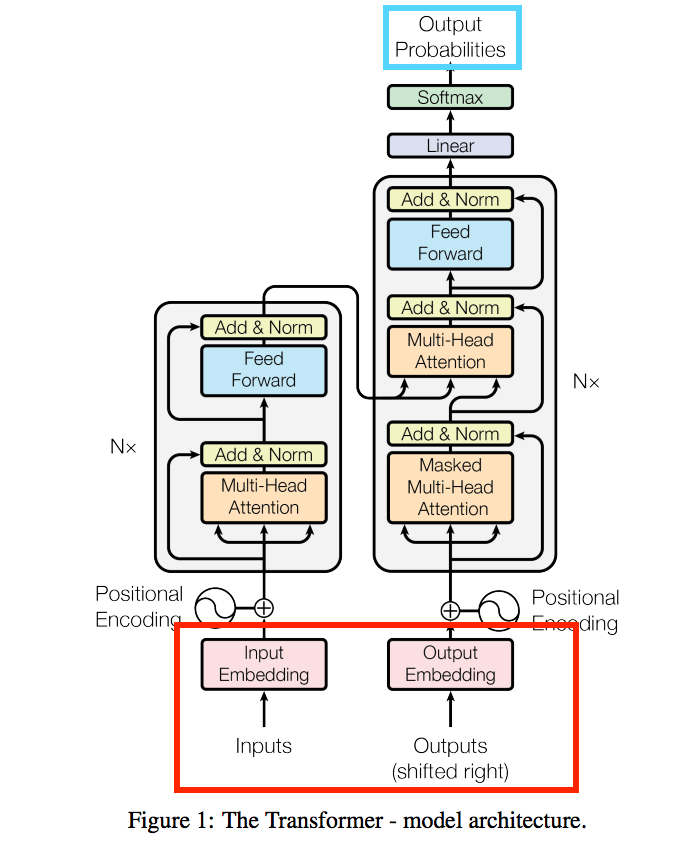
- Encoder
- input(紅框):What are you doing?
- Decoder
- input(紅框):假設目前已經解碼出2個字:你在。那在解碼第3個字時,輸入為:你在
- output(藍框):解碼第3個字後會輸出最有可能的單字:做
不過實際上在使用都是使用Embbeding的向量,上方的說明只是為了方便理解。
Multi-Head Attention
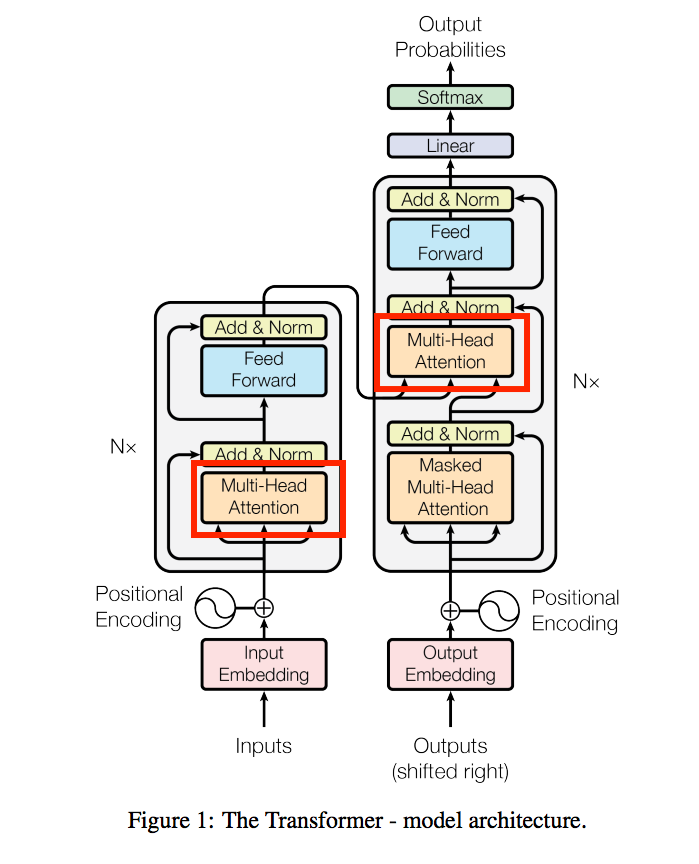
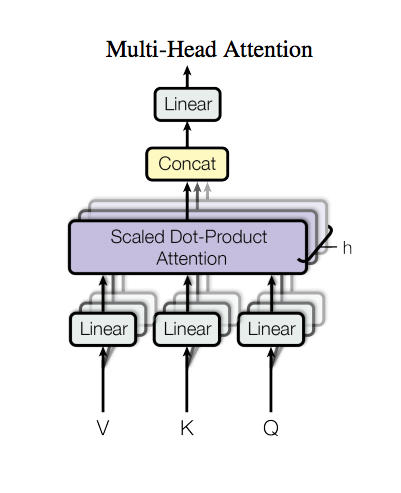
架構如上圖,Scaled Dot-Product Attention等等會提到。
我們先看這張圖有幾個地方可以探討
- 輸入部分(下方屬性都為vector)
- Q: query
- K: key
- V: value
原文:The input consists of queries and keys of dimension dk, and values of dimension dv.
In practice, we compute the attention function on a set of queries simultaneously, packed together into a matrix Q.
The keys and values are also packed together into matrices K and V .
K 和 V 是一對一對應的,就是常見的key-value。
原文一開始用不同的符號dk/dv表示各自的dimension,然而實際使用卻是dimension都設定為一樣。
概念為 Q X K 獲得一個Attention(可以理解成熱力圖/遮罩Mask,了解哪些key是重要的),然後再 X V(value)
備註:這邊的 X 是一對一相乘 dot-product
- h 個 Scaled Dot-Product Attention
這邊做的事情其實就是用好幾個(採用8個)淺的Scaled Dot-Product Attention
這邊也是被許多人說其實是CNN的概念,
但是這篇論文卻都不提CNN。
而這樣的做法優於只使用1個很深的Scaled Dot-Product Attention
Scaled Dot-Product Attention
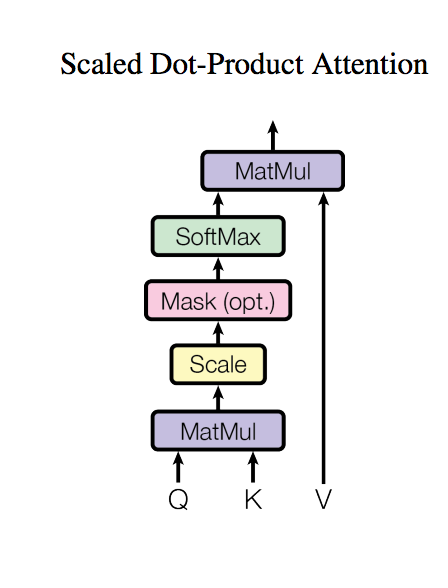
以往常用的Attention有兩種
- Additive attention
- dot-product (multiplicative) attention
此處是採用後者,但之所以叫“Scaled” Dot-Product Attention
是因為公式有做一個正規化的動作,公式如下
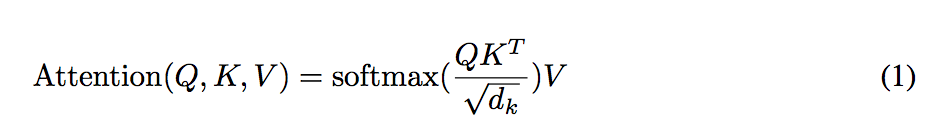
這邊給出的原因是如果不做scaled的動作,
那麼使用Additive attention的功效會較佳,
但是採用Scaled後的dot-product attention,它結果卻會比較好,因此使用scaled。
從結果來看是推測當使用dot product後,值會挺大的,
如果沒有適度的正規化,那麼softmax後的值也相對平滑,就會造成gradients的值不夠大。
至於為什麼是/這個值呢?
是因為假設是常態分佈, 標準差為0,變異數為dk。
Feed Forward(架構圖淺藍部分)
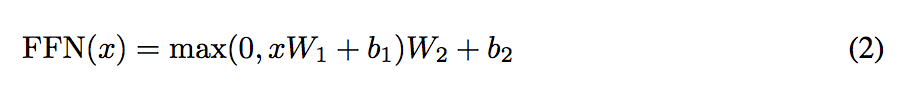
這邊其實我不太確定是在做什麼意思的。
原文:Contains a fully connected feed-forward network, which is applied to each position separately and identically.
fully connected + relu + fully connected
- input dim : 512
- hidden dim : 2048
- output dim : 512
簡單來說就是1X1 convloution的概念,
原文:Another way of describing this is as two convolutions with kernel size 1.
Encoder to decoder attention layers
這邊算是整篇論文的特點了,
encoder因為是輸入一整句話,
因此我們可以透過這個連接拿到整句話的意思,
來輔助deocder去做輸出。
但是句子很長的時候,其實我們也不需要這麼多資訊,
這時候就是Attention派上用場的時候了!!
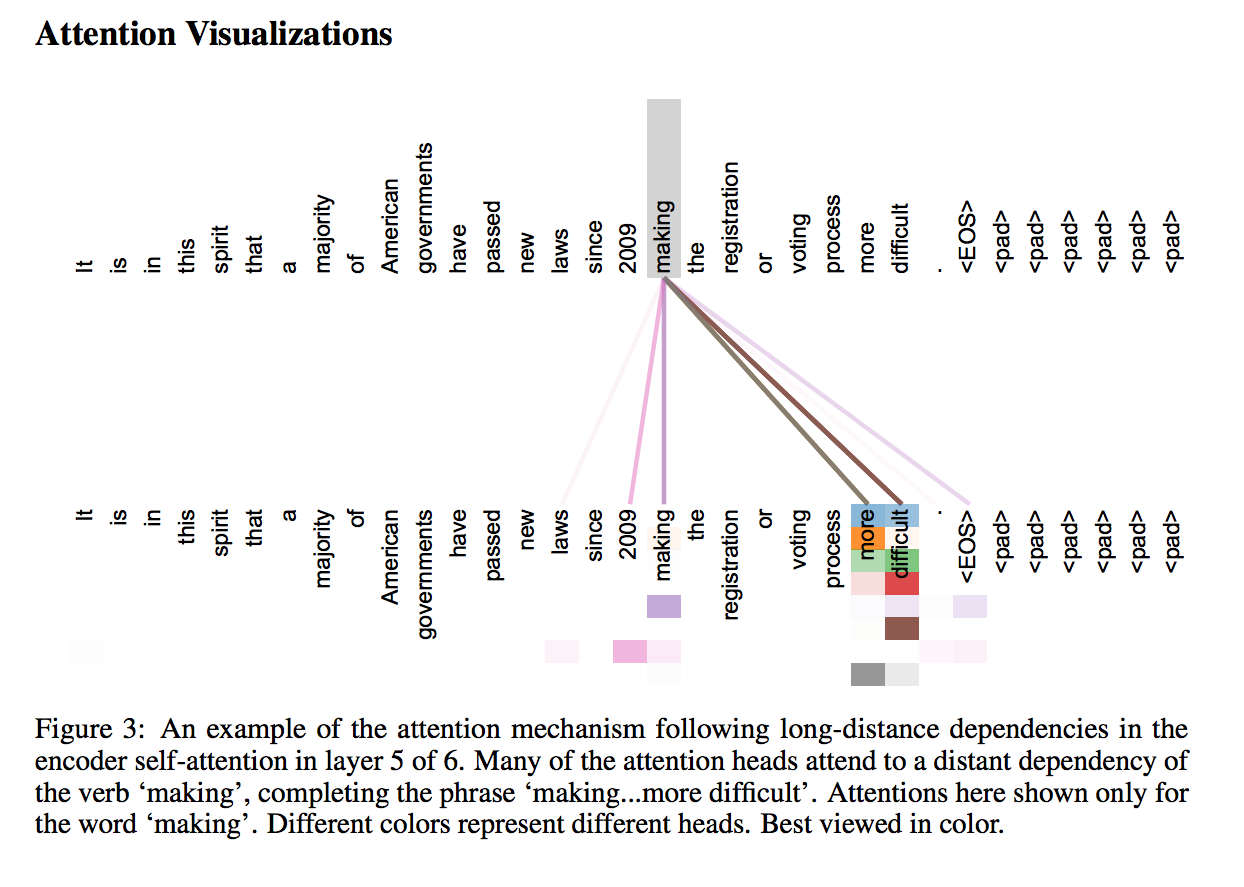
這張圖的意思簡單說就是可以從一個長的句子中,
知道我們目前應該focus在哪幾個字。
Masked Multi-Head Attention
Decoder特有的一層,
其實也是因為上面Encoder to decoder attention layers的特性而做的配套措施,
Encoder to decoder attention layers的特性是可以看到encoder的整個句子,
但是我們解碼的時後不希望還在翻譯前半段時,
就突然翻譯到後半段的句子,
透過這個Mask確保這件事。
Positional Encoding
和RNN相比,這篇論文就是Attention base的方法,因此沒有順序性。
因此我們必須要考量到句子中的每個字之間要有順序性,
因此才有這個東西,
每個輸入的Embedding要有順序。
因此透過下方的公式來達到這件事。
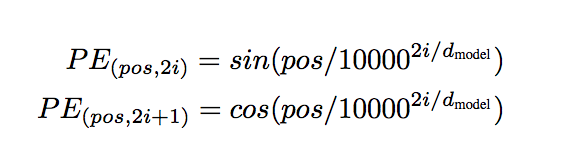
- pos : position
- i : dimension
透過sin/cos這種週期性的函數,
可以區分出距離,讓整個網路學習出順序。
更多的細節可以去看別人寫的post,
論文中也沒提到太多。
其他細節
N layers
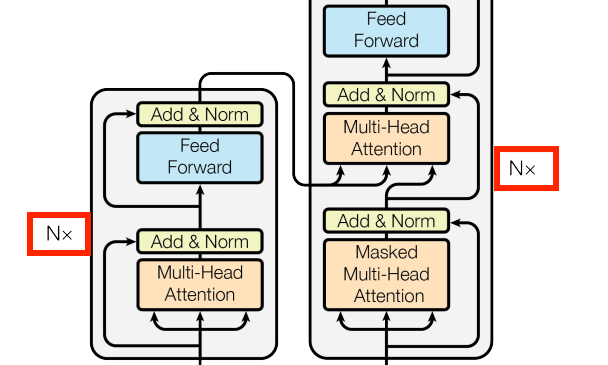
這邊其實是在說整個架構是N個(N=6)堆疊(vstack)起來,
因為總不能Encoder畫Nx2個Layer=12層
Decoder畫Nx3個Layer=18層
這樣光一張圖,論文的一頁就給他了。
Residual

就是ResNet的概念(殘差),
每個Layer都有做這樣的動作。
Add & Norm(淺綠色)
Residual + LayerNorm
output : LayerNorm(x + Sublayer(x))
Self-Attention
這名稱由來是如下圖
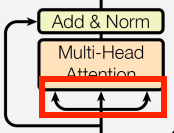
因輸入的部分都來自同一個地方 - Q: query - K: key - V: value
時間複雜度比較

最後的Self-Attention(restricted)是說我們可以限制Attention只考量附近的幾個詞彙,
看起來是很有道理,而且也可以節省複雜度。
整體而言Self-Attention base的方法與RNN的方法相比,
是非常有效率的,而且多半的時候n(句子長度) < d(embedding的維度)
成果
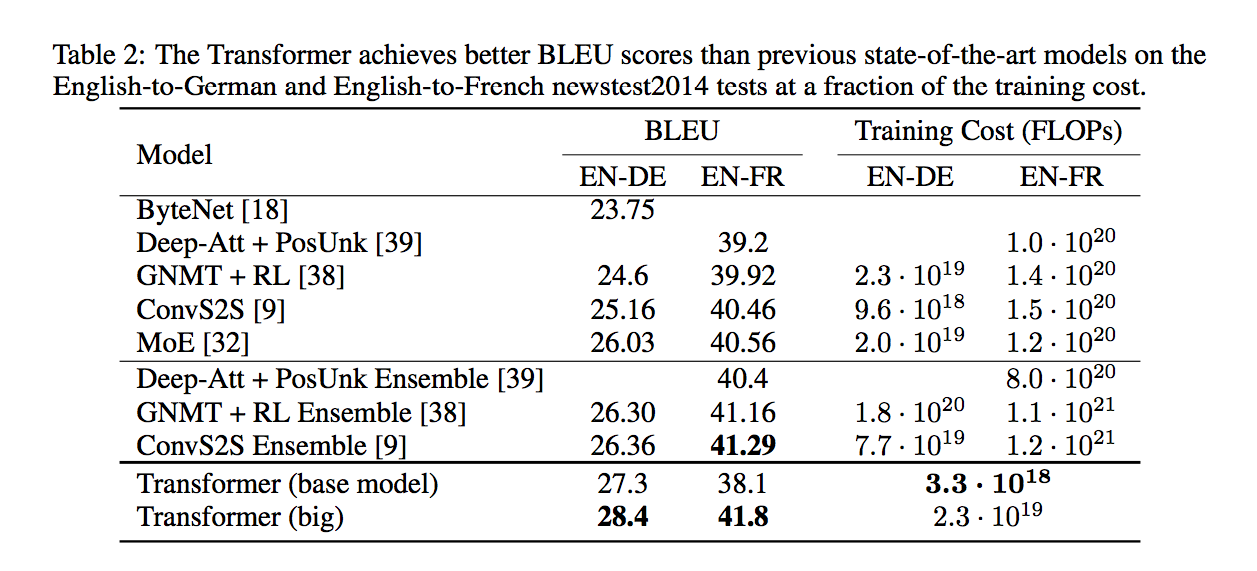
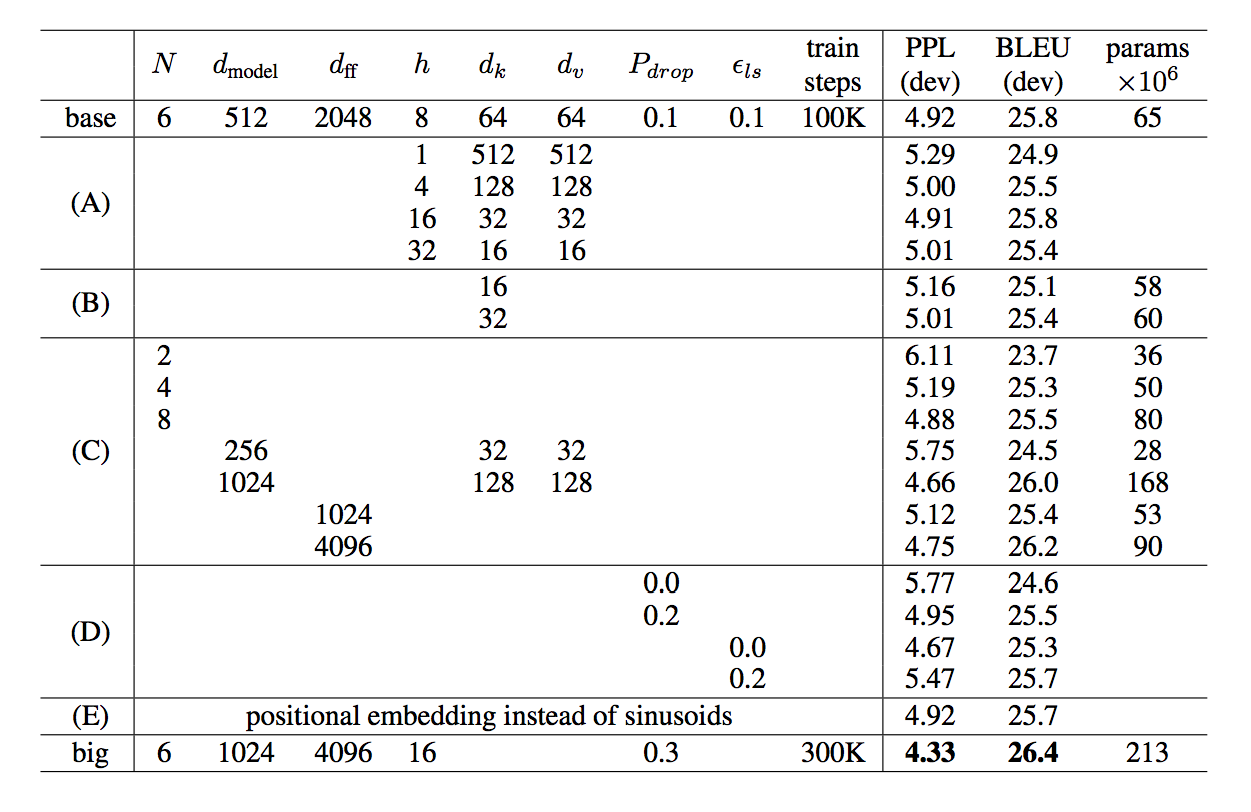
值得一提的是有用 Residual Dropout 來防止overfitting
讀後感
我覺得這篇出乎意料的難,
看了好久也翻了很多人的簡介,
如果覺得我寫的不好或是太淺,
附上幾個我覺得寫得不錯的連結:
《Attention is All You Need》浅读(简介+代码)
论文笔记:Attention is all you need
chazhongxinbitc的博客-Attention Is All You Need
參考資料:
arxiv:Attention Is All You Need(pdf)
如何理解谷歌团队的机器翻译新作《Attention is all you need》?
《Attention is All You Need》浅读(简介+代码)
chazhongxinbitc的博客-Attention Is All You Need
雷锋网完全图解RNN、RNN变体、Seq2Seq、Attention机制